Машина обратного пути — wayback machine
Содержание:
- The Ghosts of Pages Past 2: How to Use Wayback Machine
- The Ghosts of Pages Past 1: Why Might You Use Wayback Machine?
- Как найти уникальный контент для своего сайта
- Try Something with Less Energy
- Юридические проблемы с архивным контентом
- История создания Internet Archive
- Качаем сайт с web.archive.org
- Archive-It
- Ecological Awareness
- Особенности и преимущества сервиса
- Как использовать архив
- Цензура и другие угрозы
- Celebrate the Internet Archive’s 25th Anniversary!
- Инструкция по получению уникальных статей с вебархива
- mydrop.io
- Возможности использования веб-архивов
The Ghosts of Pages Past 2: How to Use Wayback Machine
Visit https://archive.org/web/
At the top of the page you’ll see a search box. Type in the domain you’d like to examine and if it has been archived you’ll see something like this:
You can use the timeline at the top of the page to select a particular year. You could also look at one of the circles in the calendar for the year you can currently see. Remember though that only days highlighted with a coloured circle have archived pages.
Hovering on a coloured circle will show you the number of snapshots Wayback Machine took on that day.
Clicking one of the snapshots takes you to the archived version of the page as it looked at that time.
You can click on any links you see on the archived page to browse an archived version of the site. You’ll then see how other pages within the site appeared at that time also.
Alternatively, you can click on the timeline at the top of the page to examine archives from a different year.
It’s that simple!
The Ghosts of Pages Past 1: Why Might You Use Wayback Machine?
What we’re gonna do right here is go back, way back, back into time.
Looking at Site Changes
The first reason you’d use Wayback Machine is to look at old versions of pages within a site.
This is useful for several reasons.
- You may have deleted a page accidentally from your site and need to reinstate it but don’t have a backup. You can possibly use Wayback Machine to recreate your lost page… if it is in the archive!
- If you’ve seen a visitor decrease to certain pages you might check to see if it’s because you changed something. You could use the Archive to look at the page and compare it to the current version.
- You might need proof that a detrimental change made in the past had nothing to do with you. Wayback Machine could prove that the change was made prior to you having access to the site.
- Wayback Machine could demonstrate your link building activities to clients. You could use it to show archived pages on sites where your inbound links appear after a certain date.
Looking at robots.txt
The Wayback Machine doesn’t only crawl and archive web pages as you can see in the pie chart above. It will also archive other file types on your domain such as your robots.txt file.
Looking at an archived version of robots.txt might give you pointers if you are having search engine crawlability problems. You could look at a past version of it to determine if any change you made caused the issues.
Checking for Intellectual Property Infringements
Let’s say you’ve seen that someone has been blatantly and illegally trading off your protected trademarks. Or maybe they’ve plagiarised your valuable intellectual property.
You may have sent a cease and desist asking the offenders to remove your intellectual property from their site.
The guilty party may have ignored your legal threats completely, so you decide upon the potentially costly path of litigation.
Your lawyer sets things in motion and all of a sudden your intellectual property disappears from the offending site to “bury the evidence”.
Wayback Machine might be able to show snapshots of the pages on their site where the infringement was committed. This would prove beyond dispute that you have been wronged.
Looking at How a Site Has Changed Over Time
If you take on a new client and want to understand how their website has evolved, Wayback Machine might be the perfect place to provide an overview.
The archive could show you technical changes made or even tell you a story of how the company has developed.
You could even use Wayback Machine in your preparation to pitch to a new client for their business. This might help you demonstrate a deeper appreciation of their story than your competitors who are also pitching.
Looking for Changed URL Structures
The URL structures for a site you manage for a client changed a while back. The organic traffic to the site fell sharply as a result. These changes weren’t documented and so nobody knows how to revert them.
In this scenario you might be able to use the archive to check URL structures and either reinstate them or set up redirections correctly.
N.B. If you’ve noticed decreased visits in Google Analytics, you can identify your historical URL structures there too.
Looking at the Historical Information Architecture of the Site
The archive might be able to show you how a website was organised in terms of the page or category hierarchy. It could even demonstrate the previous navigation structure.
This could be extremely useful when trying to understand whether categories or pages have been merged at some point. Equally it could present you with a better understanding of how past navigation structures have impacted conversion rates.
Как найти уникальный контент для своего сайта
Часто возникают ситуации, когда проекты по различным причинам закрывают, удаляя сайт с хостинга. При этом на таком ресурсе могут сохраняться полезные и интересные статьи. Через некоторое время они перестают индексироваться поисковыми системами и текст статей становится уникальным. Для владельцев информационных сайтов подобные статьи на нужную тематику представляют интерес.
Такой контент можно добавлять на собственный проект без угрозы каких-либо санкций со стороны поисковых систем, поскольку для них основное значение имеет уникальность контента на текущий момент, а не его первоисточник. Чтобы найти подходящие статьи, сэкономив время и деньги необходимые на создание собственного контента, нужно предварительно узнать список доменов, которые освободились в последнее время.
Зайдем в раздел продающихся доменов на сервисе Reg.ru, выберем категорию, совпадающую с тематикой собственного проекта, например, здоровье:
Далее выбираем подкатегорию или просматриваем все предложенные домены, выбирая из них варианты для дальнейшего анализа в веб-архиве:
После того как подходящие статьи найдены в веб-архиве необходимо проверить их на уникальность с помощью сервисов антиплагиата, например, text.ru. Если контент уникален, опубликуйте его на собственном сайте.
Try Something with Less Energy
As mentioned above, cryptocurrencies traditionally rely on energy-intensive proof-of-work as a mechanism for stability. Like the gold standard, the currency works because it is difficult to obtain, and increasingly so over time. Also like the gold standard, it’s something we may have the choice to move on from, hopefully in ways that serve our values.
The most famous foray into this change is proof-of-stake. Proof-of-work relies upon calculations that increase in complexity as the blockchain grows, requiring miners to purchase hardware and electricity as a cost of mining. Proof-of-stake is a more direct form of reinvestment; it ties up a miner’s existing coins as stake against the transaction.
Proof-of-stake is most touted for its much lower energy profile than proof-of-work. Altcoin uses it; Ethereum is switching to it; Bitcoin may or may not ever make that transition. These choices tend to be values-based. Proof-of-work’s original claim to fame was as a solution to the problem of double spending, where the same coins could be spent twice, destroying the integrity of the currency. Adherents to proof-of-work over proof-of-stake cite the importance of Bitcoin’s long-running stability across years of worldwide usage. Proof-of-stake is newer and less widespread; it’s impossible to declare it equally reliable yet, though it seems plausible that it might be. If so, the energy reduction would be worthwhile.
Юридические проблемы с архивным контентом
Некоторые дела были возбуждены против Internet Archive специально за его усилия по архивированию Wayback Machine.
Саентология
В конце 2002 года Интернет-архив удалил из Wayback Machine различные сайты, критикующие Саентологию . В сообщении об ошибке говорилось, что это было ответом на «запрос владельца сайта». Позже выяснилось, что юристы Церкви Саентологии требовали удаления, а владельцы сайта не хотели, чтобы их материалы были удалены.
Healthcare Advocates, Inc.
В 2003 году компания Harding Earley Follmer & Frailey защитила клиента от спора о товарном знаке с помощью Archive’s Wayback Machine. Адвокаты смогли продемонстрировать недействительность требований истца на основании содержания их веб-сайтов за несколько лет до этого. Затем истец, Healthcare Advocates, изменил свою жалобу, включив в нее Интернет-архив, обвинив организацию в нарушении авторских прав, а также в нарушениях Закона США » Об авторском праве в цифровую эпоху» и Закона о компьютерном мошенничестве и злоупотреблениях . Healthcare Advocates утверждали, что, поскольку они установили файл robots.txt на своем веб-сайте, даже если после подачи первоначального иска Архив должен был удалить все предыдущие копии веб-сайта истца с Wayback Machine, однако некоторые материалы продолжали оставаться быть общедоступным на Wayback. Иск был урегулирован во внесудебном порядке после того, как Wayback устранил проблему.
Сюзанна Шелл
Активист Suzanne Shell подал иск в декабре 2005 года, потребовав Internet Archive платить 100000 $ HER США для архивирования ее сайта profane-justice.org в период между 1999 и 2004 Internet Archive подал декларативное суждение иска в окружном суде Соединенных Штатов для северного округа Калифорнии на 20 января 2006 г., добиваясь судебного определения, что Internet Archive не нарушает авторские права Shell . Shell ответила и подала встречный иск против Internet Archive за архивирование ее сайта, что, как она утверждает, нарушает ее условия обслуживания . 13 февраля 2007 г. судья Окружного суда США округа Колорадо отклонил все встречные иски, за исключением нарушения контракта . Интернет-архив не стал отказываться от претензий Shell о нарушении авторских прав, связанных с ее копировальной деятельностью, которая также будет продолжена.
25 апреля 2007 г. Internet Archive и Сюзанна Шелл совместно объявили об урегулировании своего иска. Интернет-архив заявил, что «… не заинтересован во включении в Wayback Machine материалов лиц, которые не желают архивировать свой веб-контент. Мы признаем, что у г-жи Шелл есть действующие и подлежащие исполнению авторские права на свой веб-сайт, и мы сожалею, что включение ее веб-сайта в Wayback Machine привело к судебному разбирательству «. Shell заявила: «Я уважаю историческую ценность цели Internet Archive. Я никогда не намеревался мешать достижению этой цели или причинять ей какой-либо вред».
Даниил Давыдюк
В период с 2013 по 2016 год порнографический актер по имени Даниэль Давыдюк пытался удалить свои заархивированные изображения из архива Wayback Machine, сначала отправив несколько запросов DMCA в архив, а затем обратившись в Федеральный суд Канады .
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org. Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:

Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:

Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:

Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.

Долистал я до 23 октября 2017-го и вижу уже другое содержимое:

Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:

А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Archive-It
Do you or your organization have a website that needs to be indexed and archived frequently? If so, manually archiving each individual web page using the methods above can be incredibly tedious and costly. Fortunately, the Internet Archive provides a service called Archive-It that can automate the archiving process for you.
This service is not free; however, it can be ideal for those who want to back up their content with a “set it and forget it” mentality. Just stipulate which pages you would like to save and how often. This paid subscription is perfect for those who wish to save their web content on a regular basis.
Do you use the Wayback Machine? If so, do you visit it purely for fun or do you find it a useful tool? Are there other ways to back up content on the Web? Let us know in the comments!
Ecological Awareness
- We believe projects should aim to minimize ecological harm and avoid technologies that worsen environmental health.
- We value systems that work towards reducing energy consumption and device resource requirements, while increasing device lifespan by allowing repair, recycling, and recovery.
Though this principle could apply equally to any project — of course we should minimize ecological harm — it’s worth a brief exploration of the implications in the decentralized web space.
Energy use is an acknowledged issue with the decentralized web, and especially decentralized ledger (cryptocurrency) technologies, so there is a fair amount of writing in this space. Here, I’ll break down the most common takes I’ve seen folks bring up to address the ecological (usually energy-centric) impacts of this tech:
Особенности и преимущества сервиса
«Archivarix» работает напрямую с API «Веб Архива» и это — его принципиальное преимущество
В отличие от скачивания напрямую (когда скрипт просто переходит по ссылкам, имеющимся в Архиве и копирует информацию о сайте), взаимодействие с API позволяет сервису моментально обнаружить и оценить данные (их количество и целостность), что очень важно, поскольку web.archive.org нередко меняет свои алгоритмы и работает нестабильно
Кроме того, он (архив) не всегда предоставляет прямые и/или корректные ссылки, тогда как взаимодействие а АПИ — позволяет восстановить все имеющиеся компоненты сайта.
Завершив анализ и загрузку, «Архиварикс» передает данные в модуль обработки, который формирует сайт, пригодный для инсталляции на Ngix или Apache. Сервис осуществляет удаление рекламы, аналитики и счетчиков с восстановленных веб-сайтов посредством сложной и длительной проверки данных по базам рекламных провайдеров, а также сборщиков аналитики.
«Archivarix» имеет собственную CMS, которая в значительной мере облегчает восстановление и редактирование сайтов.
Как перенести контент из «Веб Архива» на WordPress?
Наличие параметра «Извлечение структурированного контента» позволит сделать WordPress блог как из восстановленного, так и из любого другого сайта.
Для этого необходимо:
1
Перейти в раздел «Восстановить сайт».
2
Выбрать опцию «Извлечь структурированный контент».
Извлечь структурированный контент
3
Нажимаем клавишу «Восстановить».
4
После окончания процесса восстановления, сервис переносит его на собственный сервер и начинает извлечение различного контента, исключая дубли, элементы управления и прочий ненужный материал. После этого на электронный адрес придет емейл с подтверждением, где выбираем пункт «Статьи» (Articles (.zip))».
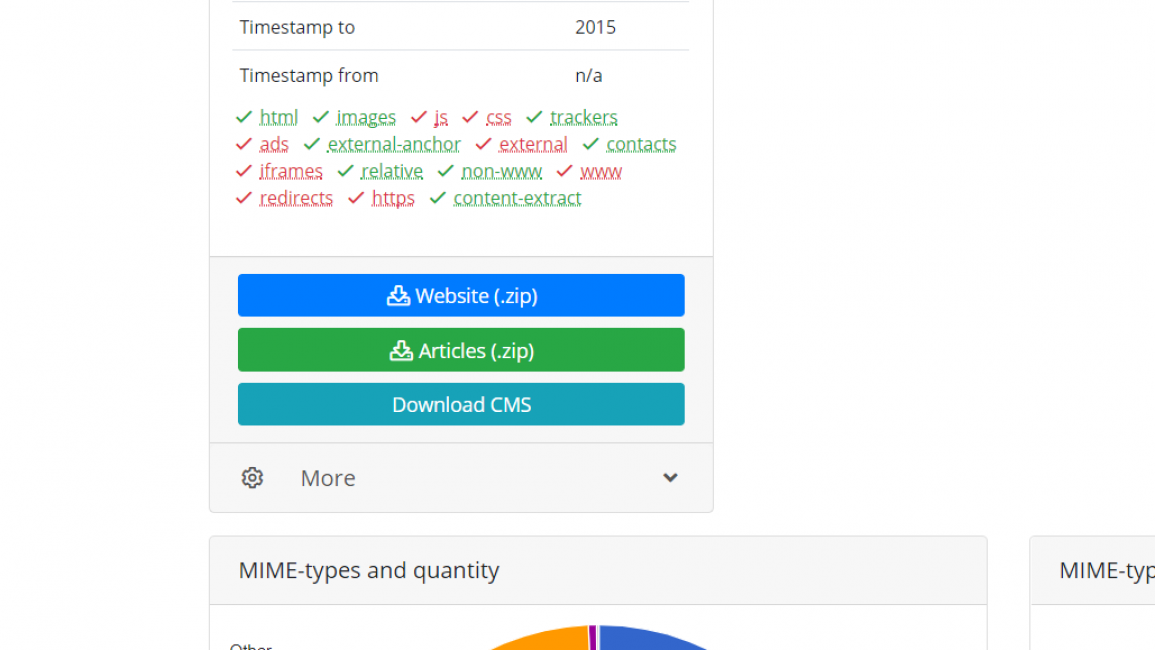
«Статьи» (Articles (.zip))»
5
Заходим в админ панель WordPress и выбираем: «Инструменты -> Импорт -> WordPress -> Запустить импорт» и выбираем файл с расширением «.wxr», который находится в скачанном zip-архиве.
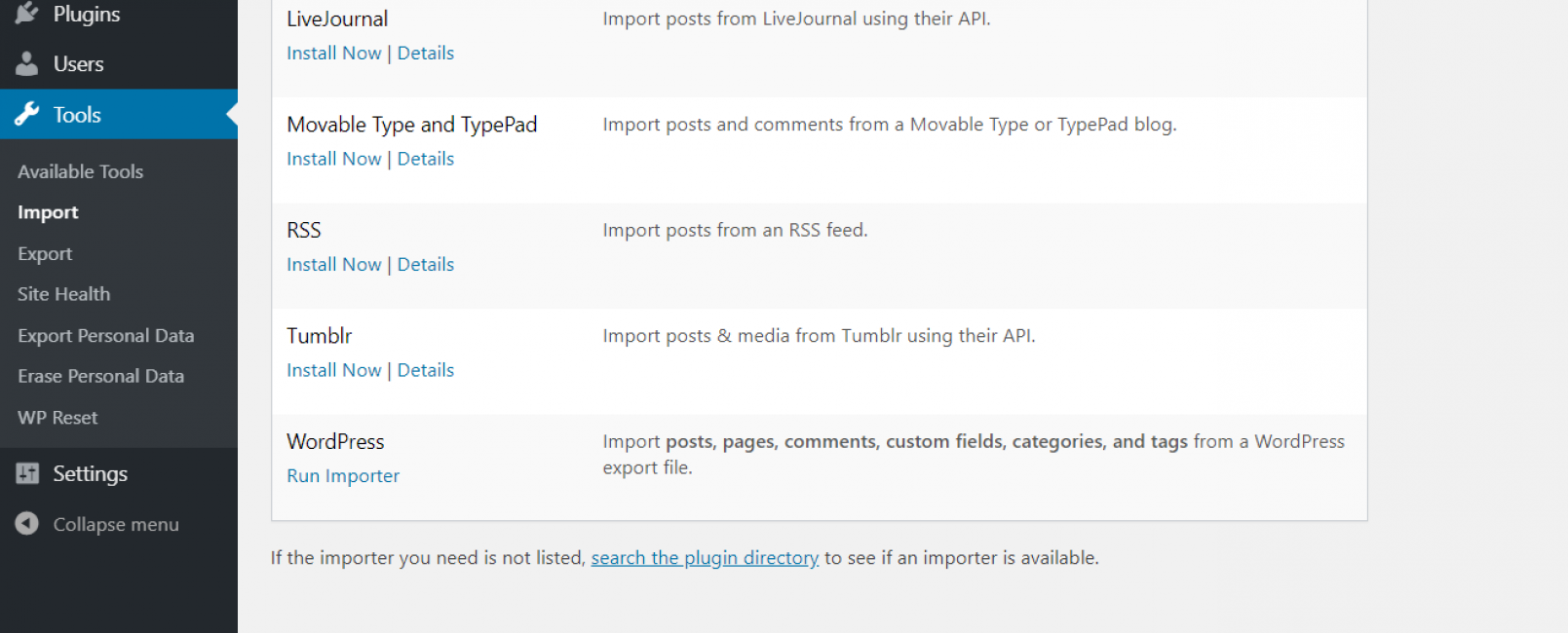
Импортируем данные
6
Если на сайте имеет большое количество изображений, то следует воспользоваться плагином для WordPress под названием Archivarix External Images Importer. Устанавливаем его и во вкладке плагина выбираем Download settings, меняем параметр Start downloading на Immediately.
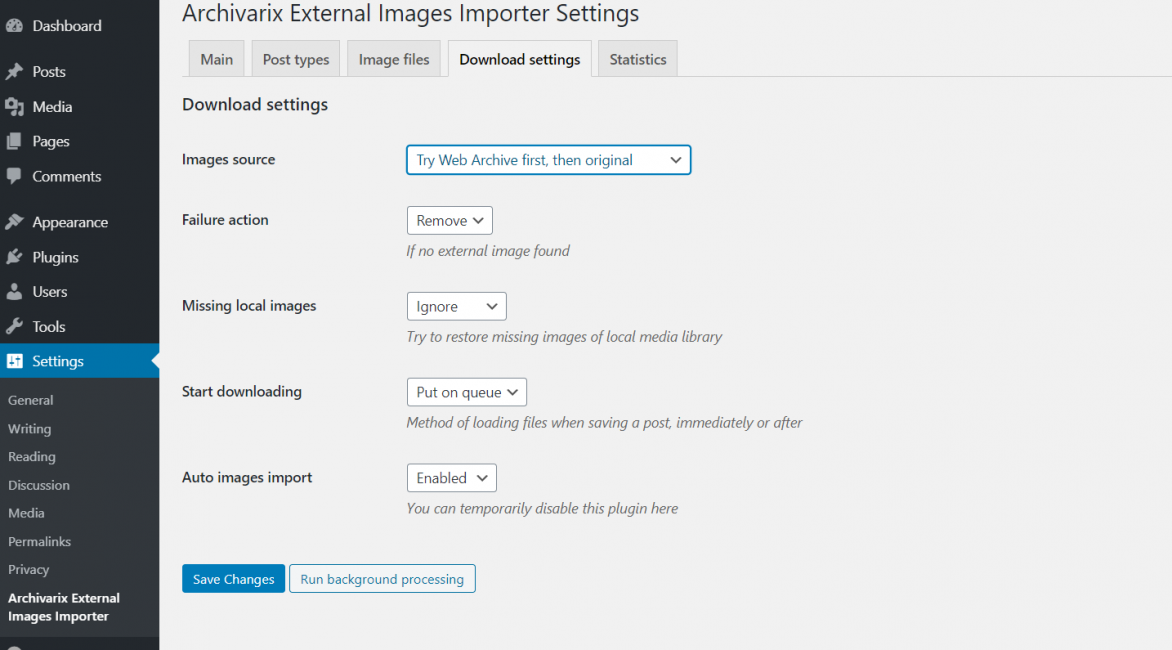
Настройка плагина изображений
Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Цензура и другие угрозы
archive.org в настоящее время заблокирован в Китае . После того, как террористическая организация «Исламское государство» была запрещена, Интернет-архив был полностью заблокирован в России в течение короткого периода в 2015–2016 годах, в котором размещалось информационное видео этой организации. С 2016 года веб-сайт вернулся и стал доступен полностью, хотя местные коммерческие лоббисты подали иск против Интернет-архива в местный суд, чтобы запретить его на основании авторских прав.
Элисон Макрина , директор проекта «Библиотечная свобода», отмечает, что «библиотекари глубоко ценят личную неприкосновенность частной жизни, но мы также категорически против цензуры».
По крайней мере, в одном случае статья была удалена из архива вскоре после того, как она была удалена с исходного сайта. Daily Beast репортер написал статью , в которой outed несколько гей — олимпийцы спортсменов в 2016 году после того, как он сделал профиль поддельного создают как гея на приложении знакомств. Daily Beast удалила статью после того, как она вызвала всеобщий фурор; Вскоре после этого Интернет-архив сделал то же самое, но решительно заявил, что они сделали это не по какой-либо другой причине, кроме как для защиты безопасности выбывших спортсменов.
Другие угрозы включают стихийные бедствия, разрушение (удаленное или физическое), манипуляции с содержимым архива (см. Также: кибератаки , резервное копирование ), проблемные законы об авторском праве и наблюдение за пользователями сайта.
Александр Роуз, исполнительный директор Long Now Foundation , подозревает, что в долгосрочной перспективе несколько поколений «почти ничего» выживут с пользой, заявляя: «Если у нас будет преемственность в нашей технологической цивилизации, я подозреваю, что многие голые данные останутся доступными для поиска и поиска. Но я подозреваю, что почти ничто из формата, в котором они были доставлены, не будет узнаваемым, «потому что сайты» с глубокими внутренними компонентами систем управления контентом, таких как Drupal, Ruby и Django, труднее заархивировать.
В статье, посвященной сохранению человеческих знаний, The Atlantic отметила, что Интернет-архив, который описывает себя как построенный на долгосрочную перспективу, «яростно работает над сбором данных, прежде чем они исчезнут без какой-либо долгосрочной инфраструктуры. из.»
Celebrate the Internet Archive’s 25th Anniversary!
As the Internet Archive turns 25, we invite you on a journey from way back to way forward, through the pivotal moments when knowledge became more accessible for all. On this anniversary page you can:
- sign up for our virtual celebration
- create a video anniversary message
- tweet about how the Internet Archive has enhanced your life & work
- dive deep into our stories, collections & important milestones in an interactive timeline
- send us a donation for our birthday!
But first, in the video above, go way back to 1996 when a young computer scientist named Brewster Kahle dreamed of building a “Library of Everything” for the digital age. A library containing all the published works of humankind, free to the public, built to last the ages. He named this digital library the Internet Archive. Its mission: to provide everyone with “Universal Access to All Knowledge.”
Инструкция по получению уникальных статей с вебархива
1. Запускаем ваш любимый браузер и вводим адрес web.archive.org.

Главная страница вебархива, где будем искать статьи
2. В поисковой строке набираем интересующую вас тематику, например «траляля»
3. Смотрим выдачу сайтов из вебархива
4. Анализируем домены по следующим признакам
4.1. Количество страниц в вебархиве должно быть больше 50

Выдача вебархива, где можно увидеть сколько страниц в архиве
4.2. Проверяем сайт на работоспособность, для этого копируем домен и вставляем в адресную строку браузера. В нашем случае это домен www.generix.com.ua, он оказался свободен.
4.3. Если же домен будет занят и на нем будет находится сайт по схожей тематике то повторите пункты 4.1 и 4.2
4.4. Проверяем таким образом все домены в выдаче вебархива и сохраняем в блокнот те домены которые нам подходят.
5. Скачиваем программу Web Archive Downloader и с помощью нее сохраняем на компьютер архивные копии сайтов, более подробно по работе с программой вы можете ознакомиться в разделе FAQ.
6. Проверяем полученные статьи на уникальность (как читайте ниже)
7. Используем полученные уникальные статьи по назначению
В принципе все, как вы видите ничего сложного нет, осталось разобраться как проверять статьи на уникальность массово. Ведь вы скачаете их
большое количество.
mydrop.io
(реф. ссылка)
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.