Популярные веб-архивы и их применение
Содержание:
- archive.md
- Проекты
- Ищем старую версию в «Яндексе»
- Примечания
- [править] Примеры
- Возможности использования веб-архивов
- Поиск сайтов в Wayback Machine
- Как проверять полученные статьи на уникальность
- Архив сайтов Internet Archive Wayback Machine
- Как пользоваться веб архивом
- Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
- ⇡#Pica Pic — коллекция ретро-игр
- Возможности использования веб-архивов
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Проекты
Wayback Machine
Логотип Wayback Machine
Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. По этой причине сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к сайтам: как и сервис кэшированных копий страниц от поисковых систем, Архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование Архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
Ищем старую версию в «Яндексе»
Интересуясь, как посмотреть старую версию страницы сайта, нельзя обойти вниманием один из самых популярных поисковиков в нашей стране. В целом механизм использования кэша «Яндекса» ничем существенно не отличается от тех же возможностей в Google
В целом механизм использования кэша «Яндекса» ничем существенно не отличается от тех же возможностей в Google.
Нужно зайти в сам поисковик, ввести в строку поиска адрес сайта и по знакомой вам уже схеме нажать на зеленую стрелку справа от ссылки на ресурс. Нажмите на меню «Сохраненная копия». Вы попадете на нужную страницу.
Меню сверху будет практически идентично тому, что было в Google — можно посмотреть текстовую версию сайта, воспользоваться поиском и узнать, каким числом была сделана резервная копия страницы.

Примечания
- (англ.). Alexa Internet. — Глобальный рейтинг сайта archive.org. Дата обращения: 20 июня 2020.
- .
- .
- (англ.). archive.org. Дата обращения: 28 марта 2019.
- . Internet Archive (7 мая 2007). Дата обращения: 31 августа 2016.
- (недоступная ссылка). Wayback Machine (6 июня 2000). Дата обращения: 1 сентября 2016.
- Jeff. (Blog). Wayback Machine Forum. Internet Archive (23 сентября 2002). Дата обращения: 4 января 2007. Author and Date indicate initiation of forum thread
- Miller, Ernest (Blog). LawMeme. Yale Law School (24 сентября). Дата обращения: 4 января 2007. The posting is billed as a ‘feature’ and lacks an associated year designation; comments by other contributors appear after the ‘feature’
- Maximillian Dornseif. (англ.). preprint cs/0404005 16. arXiv (2004). Дата обращения: 26 ноября 2017.
- .
- .
- (недоступная ссылка). Дата обращения: 17 сентября 2017.
- . Роскомнадзор (24 октября 2014).
- ↑
[править] Примеры
Роскомнаха банит архивы интернета (Блюстители)
- web.archive.org — старейший веб-архив, сохраняющий копии сайтов с 1996 года в автоматическом режиме в определённые промежутки времени. Имеет юридический статус библиотеки, является некоммерческой организацией. Сайт обладает несколькими зеркалами. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ за страницу «Одиночный Джихад» (а ещё ранее — за страницу с видеороликом «Звон мечей» террористической группировки ИГИЛ, запрещённой в РФ). В начале июля доступ к сайту был возозбновлён в связи с переносом материала в отдельный архив, доступный для закачки. Позже снова заблокирован, но по состоянию на 2020 год уже удалён из реестра.
- peeep.us — совмещенный с сокращателем ссылок сайт, позволяющий сохранять страницы самим пользователям. Создаёт зеркало страницы на фиксированный момент времени, который отображается вверху жёлтой полосой, с сокращённым URL-адресом. В отличие от веб-архива, щёлкая по ссылкам, открываются веб-страницы на текущий момент времени, а не в архиве. В отличие от archive.is, может сохранять страницы, для просмотра которые видны только сохраняющему, но не остальным людям. Не сохраняет картинки и фреймы. На 25 июня 2015 года был внесён в реестр запрещённых сайтов и заблокирован на территории РФ, позднее вообще перестал открываться. На июль 2015 года на месте сайта выдаётся ошибка 404. Был разблокирован в начале сентября 2015 года.
- archive.is — сайт, аналогичный peeep.us. Отличается тем, что сохраняет не только основной html-файл страницы, но также и все картинки, стили, фреймы и фонты. Также умеет сохранять страницы с Web2.0-сайтов, например с twitter.com.
Также в роли веб-архивов выступают кеши поисковых систем, но в отличие от первых, они ненадёжны, поскольку могут быстро удаляться. Наибольший срок хранения страниц замечен за Яндексом.
В викисреде
Роль веб-архивов могут выполнять отдельные разделы сайтов, которые сами по себе ими не являются:
Копипаста Луркоморья — сборник заинтересовавших пользователей Луркоморья текстов со страниц Интернета или взятые из книжных источников.
Архивы Викиреальности — сохраняет заслуживающие внимание страницы и творчество, связанное с викисредой. Для архивов выделено специальное пространство имён.
Авторские проекты в Традиции (например, творчество АПЭ, Погребного и т. п.) — сборник творчества различных авторов, которое (в большинстве своём) ранее где-то выкладывалось.
Возможности использования веб-архивов
Возможности сохраненной истории Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
Фиксация в веб-архиве за 2011–2016 годы Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «https://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта

Уникальный контент из веб-архива Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URL https://www.nic.ru/auction/forbuyer/download_list.shtml#buying в строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
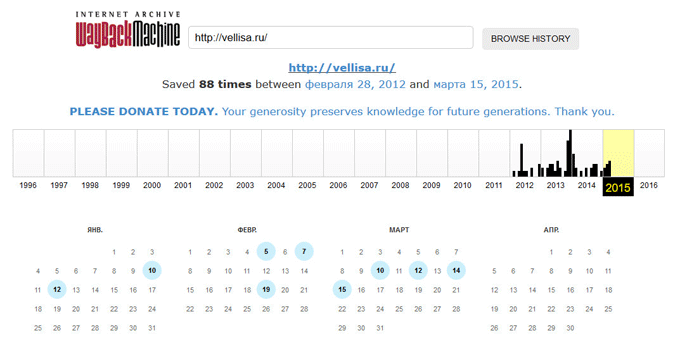
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
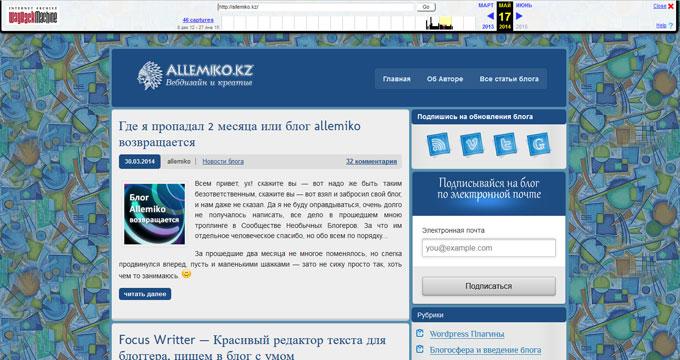
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.

На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
Как проверять полученные статьи на уникальность
Есть несколько способов проверки статей на уникальность и наверное многие из них вам известны. Тем не мене здесь мы приведем лучшие способы проверки контента на уникальность.
- Проверка статей с использованием специализированных сервисов типа etxt.ru, text.ru или адвего. Данный способ подходит когда нужно проверить одну или две статьи, так как проверка занимает длительное время и существуют ограничения по количеству проверок в день с конкретного IP адреса.
- Если вам не жалко немного денег, то для ускорения процесса можно использовать пакетную проверку статей предоставляемую такими сервисами.
- Использовать специализированное программное обеспечение для проверки уникальности статей типа Advego Plagiatus.

Программа для проверки уникальности статей из Вебархива
После чего открываем программу и загружаем наши статьи для пакетной проверки используйте меню программы: «Операции -> Пакетная проверка».

Настройка программы для проверки уникальных статей из вебархива
Если у вас отсутствует необходимость проверять много статей, то просто включите отображение каптчи и вводите ее вручную.
На этом пожалуй все. Мы рассмотрели как можно получить множество уникальных статей абсолютно бесплатно. Желаем вам удачи !
Ссылки используемые в статье
- 1. web.archive.org – интернет архив веб сайтов
- 2. Web Arhcive Downloder – это уникальная программа для сохранения сайтов из интернет архива.
Архив сайтов Internet Archive Wayback Machine
Скрыть рекламу в статье
Архив сайтов Internet Archive Wayback Machine
Каждый, кто собирал информацию по интересующей его проблеме за достаточно длительный период, знает, как порой бывает важно найти сведения, опубликованные на сайте несколько лет назад. Иногда это просто необходимо: в частности, в случае обнаружения новых тенденций в развитии объекта, которое требует ретроспективной оценки времени их появления
Либо возникновения новой темы для изучения событий на рынке и, как следствие, сравнения реакции на них с тем, как вели себя в подобной ситуации участники рынка в прошлом. Конечно, специалист конкурентной разведки всегда старается архивировать интересующую его информацию. Однако в реальной жизни бывает так, что проблема просто не входила в сферу его интересов до определенного момента либо на предприятии эта служба появилась позже тех событий, которые и стали предметом ее пристального внимания.
В таком случае на помощь нередко может прийти сервис, который нам также рекомендовал Arthur Weiss. Этот Internet Archive Wayback Machine, его изображение представлено на рис. 21. Сервис позиционируется как «Библиотека Интернета». Пауки, принадлежащие Internet Archive Wayback Machine, посещают веб-сайты и сохраняют архивную копию на сервере «библиотеки». Как написано на странице этого ресурса, интересующего нас сайта может и не оказаться в архиве. Например, в случае если паук не может его прочитать, поскольку тот защищен одним из способов, описанных нами в соответствующем разделе данной книги.
Сервис Internet Archive Wayback Machine некоммерческий. Он работает с 1996 г. и, как утверждают его владельцы, существует на пожертвования меценатов и благодаря технической поддержке крупных интернет-компаний, таких как Alexa. Ежемесячно архив увеличивается в объеме на 20 терабайт. Ценным нам видится то обстоятельство, что Internet Archive Wayback Machine отслеживает копии даже тех сайтов, которых больше не существует в Сети.
Для того, чтобы увидеть сохраненную версию нужного сайта, достаточно ввести в окно, расположенное в верхней части главной страницы, адрес ресурса и нажать клавишу «Take me Back». После этого пользователю будет предложен архив по запрошенному ресурсу. В пределах этого архива можно ознакомиться с копией сайта за искомую дату. На рис. 22 показан список копий ресурса «Росбизнесконсалтинг».
Рис. 21. Главная страница Internet Archive Wayback Machine.
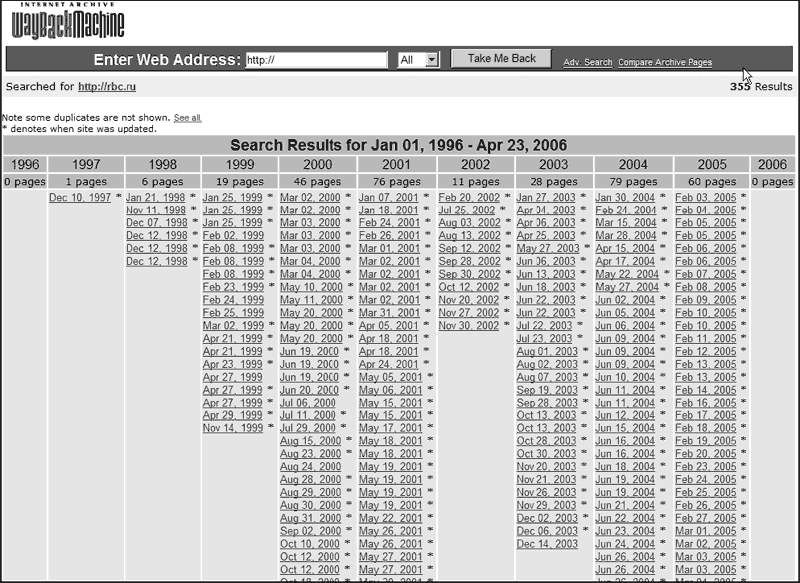
Архив, расположенный на сервере в Сан-Франциско, поражает своими возможностями. Вот как выглядела страница этого известнейшего интернет-ресурса 10 декабря 1997 г. (рис. 23).

Рис. 23. Страница ресурса РБК от 10 декабря 1997 г.
Надо сказать, что, помимо функций обеспечения нужд непосредственно конкурентной разведки, наши источники рассказывали о случаях, когда этот ресурс помогал компаниям в сборе доказательств по фактам информационной войны против них. Как правило, в таких ситуациях, когда нападающая сторона «затирала» сведения на сайте, Internet Archive Wayback Machine позволял доказать факт распространения порочащих организацию данных.
Один из источников автора сообщил о факте, когда наличие копии сайта в архиве Internet Archive Wayback Machine позволило доказать в споре с контролирующими органами, что сайт, существование которого вызывало сомнения у контролеров, действительно существовал в тот период, когда компания получила деньги за его разработку и «раскрутку».
Оглавление книги
Как пользоваться веб архивом
Если вы хотите выполнить поиск в архиве веб-страниц, введите в адресную строку вашего браузера адрес web.archive.org.ru, после чего в поле поиска укажите адрес интересуемого сайта. Например, введите адрес домашней страницы Яндекса http://yandex.ru и нажмите клавишу «Enter».

Сохраненные копии главной страницы Яндекс на сайте web.archive.org
Зелеными кружочками обозначены даты когда была проиндексирована страница, нажав на него вы перейдете на архивную копию сайта. Для того чтобы выбрать архивную дату, достаточно кликнуть по временной диаграмме по разделу с годом и выбрать доступные в этом году месяц и число. Так же если вы нажмете на ссылку «Summary of yandex.ru» то увидите, какой контент был проиндексирован и сохранен в архиве для конкретного сайта с 1 января 1996 года ( это дата начала работы веб архива).

Какой контент сохраняет веб-архив интернета
Нажав на выбранную дату, вам откроется архивная копия страницы, такая как она выглядела на веб-сайте в прошлом. Давайте посмотрим на Яндекс в молодости, ниже приведен снимок главной страницы Яндекса на 8 февраля 1999 года.

Веб архив копия сайта Яндекс на 08.02.1999
Вполне возможно, что в архивном варианте страниц, хранящемся на веб-сайте Archive.org, будут отсутствовать некоторые иллюстрации, и возможны ошибки форматирования текста. Это результатом того, что механизм архивирования веб-сайтов, пытается, прежде всего, сохранить текстовый контент web-сайтов. Помните об еще одном ограничении онлайн-архива. При поиске конкретного контента, размещенного на определенной архивной странице, лучше всего вводить ее точный адрес, а не главный адрес данного веб-сайта.
Возвращаясь к нашему примеру: вы получили доступ к архивному контенту, размещенному на главной странице Яндекса, при нажатии на ссылки в архивной версии могут как загружаться так и не загружаться другие страницы сайта. Так в нашем варианте страница «последние 20 запросов» была найдена, а вот страница «Реклама на yandex.ru» не нашлась.
Подводя итоги можно сказать, что web.archive.org поистине уникальный и грандиозный проект. Он действительно является машиной времени для интернета, позволяя найти удаленные сайты и их архивные версии . Как использовать предоставляемые возможности решать только вам, но использовать их можно и нужно обязательно !
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web.archive.org/ и в поисковой строке ввести адрес веб-ресурса.
 После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
 Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
 Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page
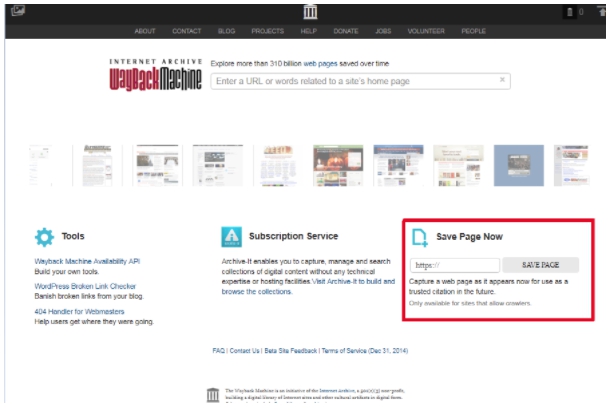 Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
⇡#Pica Pic — коллекция ретро-игр
В современных компьютерных играх можно строить целые цивилизации или прыгать с ракеткой перед огромным экраном, играя в настольный теннис с воображаемым противником. Каких-то 20 лет назад электронные игры были совсем иными, но занимали они не меньше. Вспомните хотя бы электронную игру «Волк с яйцами» (в некоторых моделях вместо волка сползающие яйца собирал Микки Маус), известную, наверное, любому школьнику конца восьмидесятых-начала девяностых. Нынешнему поколению трудно представить, как в такое можно играть, но тогда эта незамысловатая игрушка для многих была предметом мечтаний.

Ресурс Pica Pic предлагает огромную коллекцию подобных электронных ретро-игр, которые продавались в разных странах мира лет 20-30 назад. Возле каждой игры можно прочитать информацию о том, где и в каком году ее выпустили. Но самое главное, что в «волка с яйцами» и в другие ретро-игры можно поиграть прямо в браузере и даже сравнить свои результаты с рекордами других игроков.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
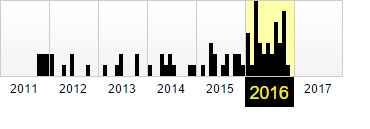 Фиксация в веб-архиве за 2011–2016 годы
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
 Уникальный контент из веб-архива
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.