Изучаем управление базами данных: — 7 лучших бесплатных систем с открытым исходным кодом
Содержание:
- Нормализация базы данных
- Создание пользователя с использованием SSMS
- Создаем базу данных
- По каким данным можно проверять человека
- Как хранится информация в БД
- Список полезной литературы
- Добавление индексов и представлений
- Преимущества проверки человека через онлайн сервис Чеклик
- Планы на будущее
- Общая система типов
- Модели и работа с данными
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:
Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:
Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:
В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:
Создание пользователя с использованием SSMS
-
В обозревателе объектов раскройте папку Базы данных .
-
Разверните базу данных, в которой создается новый пользователь базы данных.
-
Щелкните правой кнопкой мыши папку Безопасность, выберите пункт Создать, а затем Пользователь… .
-
В диалоговом окне Пользователь базы данных — создание на странице Общие выберите один из следующих типов пользователей в списке Тип пользователя:
-
пользователь SQL с именем для входа
-
пользователя SQL с паролем
-
Пользователь SQL без имени для входа
-
Пользователь, сопоставленный с сертификатом
-
Пользователь, сопоставленный с асимметричным ключом
-
пользователя Windows
-
-
Когда вы выбираете вариант, остальные параметры в диалоговом окне могут поменяться. Некоторые варианты применимы только к определенным типам пользователей базы данных. Некоторые параметры можно не заполнять. В результате будут использоваться значения по умолчанию.
User name
Введите имя нового пользователя. Если выбрать элемент Пользователь Windows в списке Тип пользователя, вы можете также щелкнуть многоточие (…) и открыть диалоговое окно Выбор пользователя или группы.Имя входа
Введите имя входа для пользователя. Также можно щелкнуть многоточие (…) , чтобы открыть диалоговое окно Выбор имени входа. Имя входа доступно, если выбрать элемент SQL-пользователь с именем входа или Пользователь Windows в списке Тип пользователя .Пароль и Подтверждение пароля
Введите пароль для пользователей, которым требуется доступ к базе данных.Язык по умолчанию
Укажите язык по умолчанию для пользователя.Схема по умолчанию
Укажите схему, которая будет владеть объектами, созданными пользователем. Также можно щелкнуть многоточие (…) , чтобы открыть диалоговое окно Выбор схемы. Схема по умолчанию доступна, если выбрать элемент SQL-пользователь с именем входа, SQL-пользователь без имени входа или Пользователь Windows в списке Тип пользователя .Имя сертификата
Укажите сертификат для пользователя базы данных. Также можно щелкнуть многоточие (…) , чтобы открыть диалоговое окно Выбор сертификата. Имя сертификата доступно, если выбрать элемент Пользователь, сопоставленный с сертификатом в списке Тип пользователя .Имя асимметричного ключа
Введите ключ для пользователя базы данных. Также можно щелкнуть многоточие (…) , чтобы открыть диалоговое окно Выбор асимметричного ключа. Имя асимметричного ключа доступно, если выбрать элемент Пользователь, сопоставленный с асимметричным ключом в списке Тип пользователя . -
Нажмите кнопку ОК.
Дополнительные параметры
Диалоговое окно Пользователь базы данных — создание также содержит параметры на четырех дополнительных страницах: Собственные схемы, Членство, Защищаемые объекты и Расширенные свойства.
-
На странице Собственные схемы перечислены все возможные схемы, которые принадлежат новому пользователю базы данных. Чтобы добавить схему для пользователя базы данных или удалить ее, на вкладке Схемы, принадлежащие этому пользователю установите или снимите флажки для соответствующей схемы.
-
На странице Членство приведен список всех ролей, к которым может принадлежать новый пользователь базы данных. Чтобы добавить роль для пользователя базы данных или удалить ее, на вкладке Членство ролей базы данных установите или снимите флажки для соответствующей роли.
-
На странице Защищаемые объекты перечислены все возможные защищаемые объекты и разрешения на эти объекты, которые могут быть предоставлены для имени входа.
-
Страница Расширенные свойства позволяет добавлять пользовательские свойства пользователям базы данных. На этой странице доступны следующие параметры.
База данных
Отображает имя выбранной базы данных. Это поле доступно только для чтения.Параметры сортировки
Отображает параметры сортировки, используемые для выбранной базы данных. Это поле доступно только для чтения.Свойства
Просмотрите или укажите расширенные свойства объекта. Каждое расширенное свойство состоит из пары имя/значение метаданных, связанных с объектом.Кнопка с многоточием (…)
Нажмите многоточие (…) рядом с полем Значение, чтобы открыть диалоговое окно Значение для расширенного свойства. Введите или просмотрите значение расширенного свойства в этом более просторном окне. Дополнительные сведения см. в разделе Диалоговое окно «Значение для расширенного свойства».Удаление
Удаляет выбранное расширенное свойство.
Создаем базу данных
Управление базами данных как объектами
Будем считать, что наша небольшая экскурсия по запросам и командам SQL со стороны «торгового зала» завершена. Заглянем теперь в его «служебные помещения» и познакомимся с тем, как создается сама база данных. Эта часть языка SQL не столь стандартизирована и сильно отличается в различных реализациях. Поэтому в дальнейших примерах я буду придерживаться синтаксиса, принятого в самой популярной на веб-серверах системе — MySQL.
MySQL — продукт шведской компании MySQL AB. Ее основатели — Дэвид Аксмарк, Аллан Ларсон и Майкл Видениус (последний больше известен по прозвищу — Монти). По одной из версий, первая часть названия продукта (My) — не что иное, как англизированная запись имени дочери М. Видениуса. Однако точно за происхождение названия сегодня не могут поручиться даже отцы-создатели. Существует версия, по которой «my» — это префикс, с которого начинались названия рабочих каталогов на их компьютерах.
Из всех команд чаще всего нам будут нужны три: CREATE (создать), ALTER (изменить) и DROP (уничтожить).
Чтобы создать новую базу данных с названием, ну скажем, OUR_SHOP, следует выполнить команду:
Еще лучше сразу при ее создании установить нужную кодировку (ведь по умолчанию в MySQL используется latin1). В итоге команда будет выглядеть так.
Если вы забыли сделать это сразу, не беда. Для того и существуют команды по изменению:
Когда, наигравшись вдоволь с пробной базой данных, вы захотите ее уничтожить, воспользуйтесь командой:
Управление таблицами
Чтобы создать таблицу GOODS, на которой мы отрабатывали манипуляции с данными, потребуется составить команду примерно такого вида:
Разберем эту команду подробнее. Тип INT устанавливается для столбцов с целочисленными данными, тип VARCHAR(100) обеспечивает хранение строк с длиной не более 100 символов, DECIMAL(10,2) соответствует действительным числам с не более чем десятью знаками и точностью в два знака после запятой.
Столбец ID объявлен первичным ключом (PRIMARY KEY).
Ключевое слово AUTO_INCREMENT означает, что при добавлении новых строк с неуказанным значением ID оно будет автоматически заполняться следующим значением. Это удобно, поскольку обычно нет нужды вручную указывать значения первичных ключей, а за тем, чтобы они были уникальными, пусть лучше следит база данных.
NOT NULL означает запрет на пустые значения в столбце, иными словами, гарантирует обязательность заполнения.
Команда DEFAULT задает значение по умолчанию — то, которое будет записываться в базу при добавлении новой строки, если не указано иное. В нашем случае она обеспечивает автоматическое объявление товара штучным (код = 1) в случае, если при добавлении новых строк не будет указан другой код.
Признак UNIQUE обеспечивает уникальность значений в колонке (в нашем случае — уникальность названий товаров).
Если в будущем вы захотите перенастроить объявленные командой CREATE столбцы таблицы, сделать это можно командой ALTER. Например, таблицу GOODS можно нарастить строчной колонкой REMARK (подкоманда ADD):
Поработав с ней немного и убедившись, что 50 символов для примечания явно недостаточно, увеличиваем максимальный размер строки до 250 (блок CHANGE):
Так как имя столбца мы не изменяли (новое совпадает со старым), то его просто повторяем в этой команде (как бы меняем само на себя).
И наконец, убедившись через какое-то время, что без примечания в товарном справочнике вполне можно обойтись, мы удаляем ставшую ненужной колонку (блок DROP):
Удалить таблицу целиком можно командой DROP:
Стоит ли говорить о том, что пользоваться командами с этим ключевым словом следует с особой осторожностью?
По каким данным можно проверять человека
Интернет предоставляет неограниченные возможности пользователям. Узнать какие-либо сведения о конкретном человеке можно как с помощью официальных баз данных, которые ведутся государственными органами и иными ведомствами, так и с помощью онлайн-сервисов.
Рассмотрим способы проверки физического лица с учетом имеющихся документов, данных:
- Паспорт;
Владея информацией о серии и номере паспорта можно узнать о том, действителен ли он или нет. Сделать это нужно с помощью сервиса «Проверка по списку недействительных российских паспортов». Актуальную базу данных предоставляет главное управление по вопросам миграции МВД России.
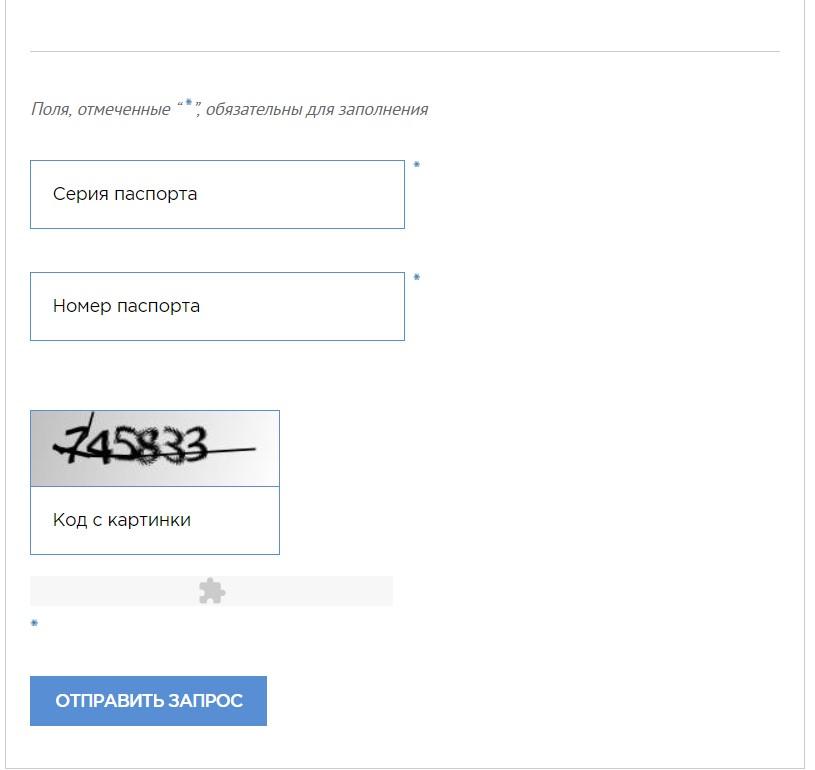
Алгоритм действий довольно простой: в свободных полях вводим серию и номер паспорта человека, ниже – код с картинки. Далее нажимаем кнопку «Отправить запрос» и ждем ответ от системы. Пользователь узнает, есть ли паспорт среди недействительных или нет.
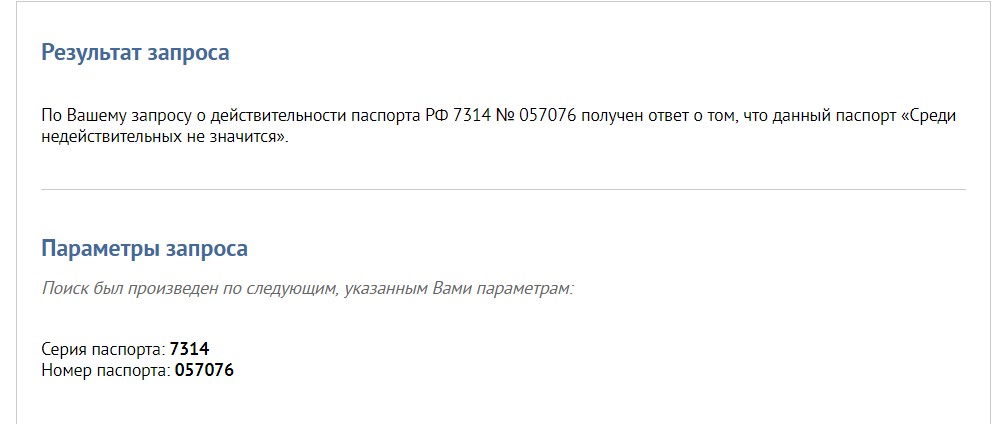
Следующий сервис, который нам даст информацию по данным из паспорта – «Как узнать ИНН».
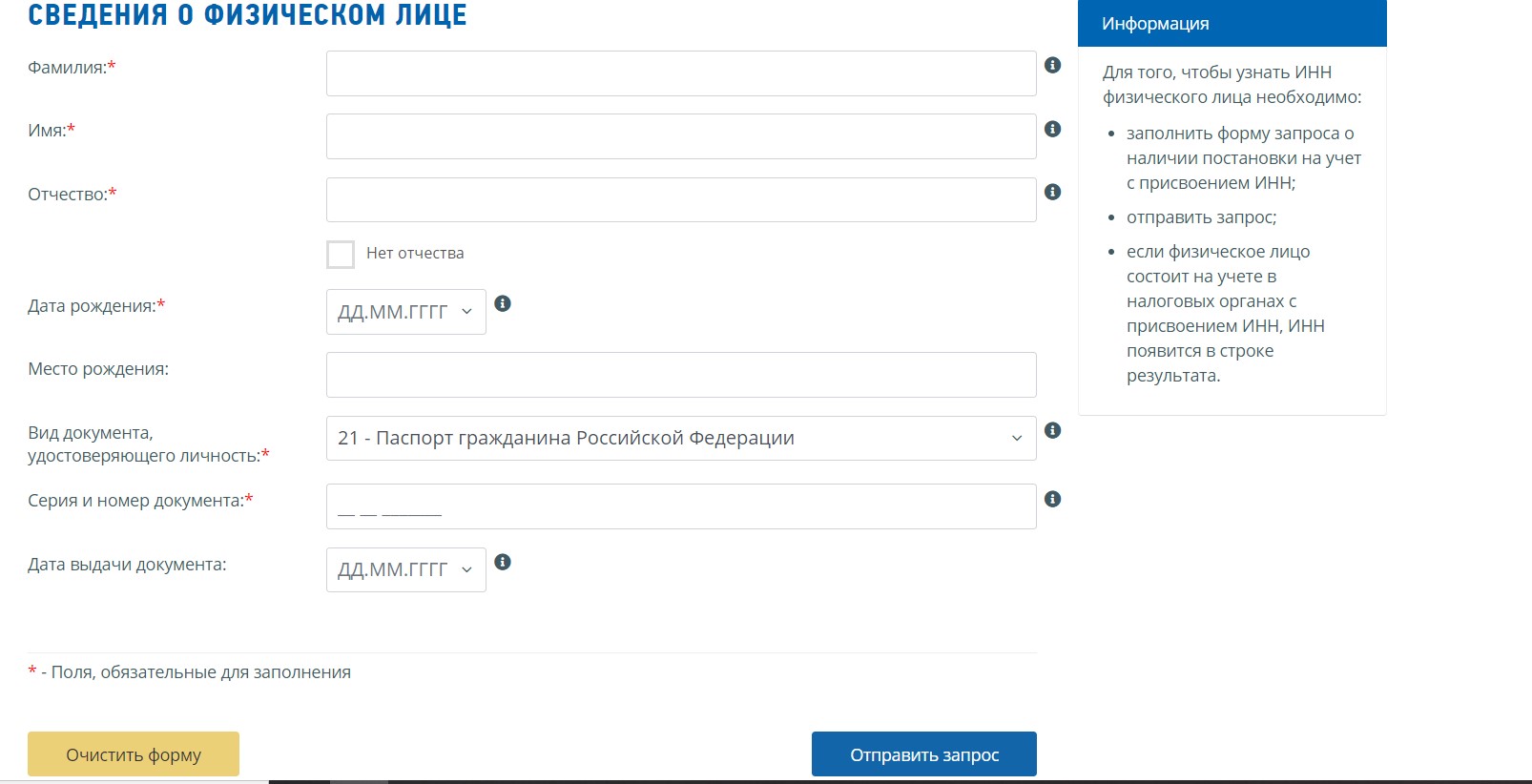
Пользователю необходимо заполнить следующие поля:
- Паспорт;
- Фамилия;
- Имя;
- Отчество;
- Дата рождения;
- Серия и номер паспорта.
Далее нажимаем кнопку «Отправить запрос». После обработки данных система выдаст номер ИНН, если он имеется в базах или сообщит об его отсутствии.

По ФИО с помощью онлайн сервисов можно узнать следующие сведения:
- Информацию об имеющихся судебных делах людей.
Для этого необходимо посетить районный суд по месту регистрации гражданина
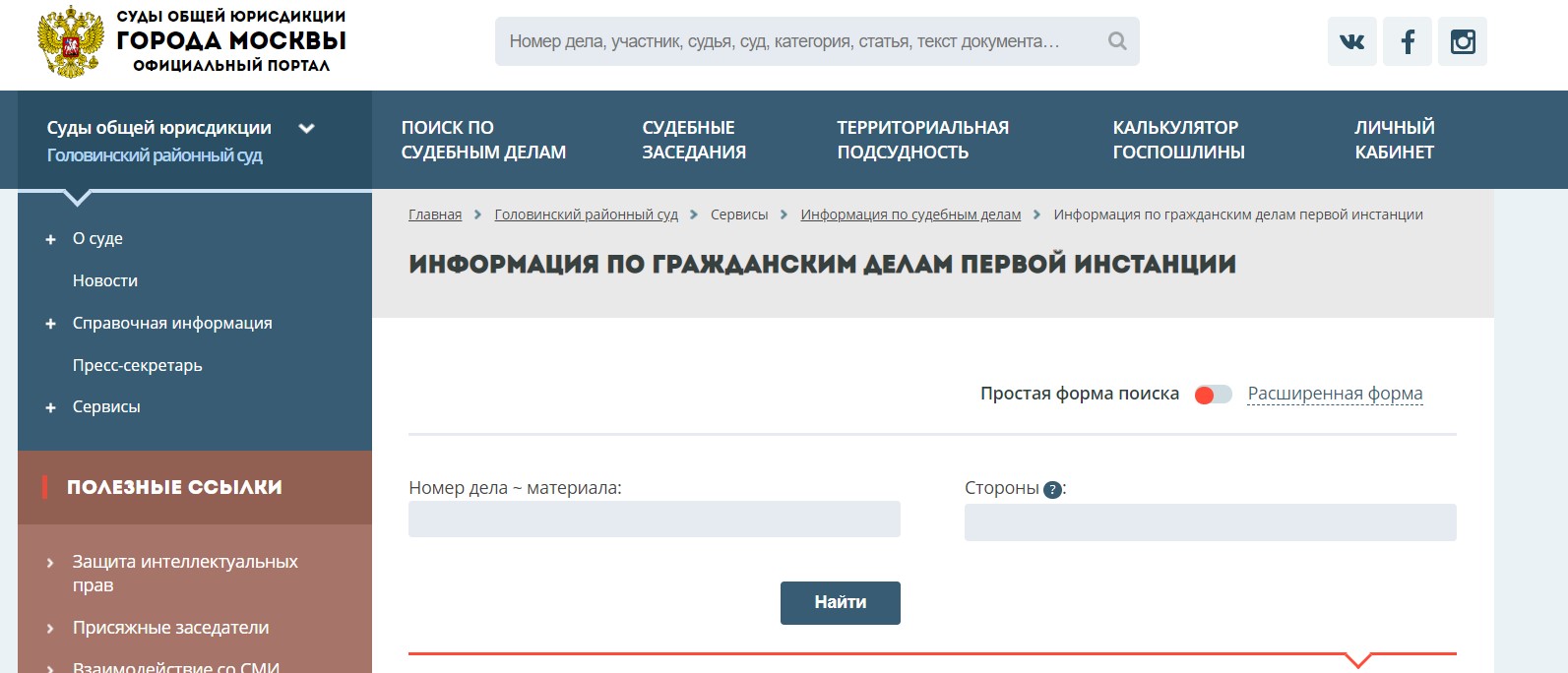
Второй вариант — обратиться в картотеку арбитражных дел, если имеет место быть ИП или если человек участвует в организации в качестве учредителя или члена.
Наличие актуальных исполнительных производств и, соответственно, задолженностей.
Сервис ФССП «Банк данных исполнительных производств».
После введения ФИО людей, система выдаст данные об имеющихся в производстве у приставов исполнительных документах.
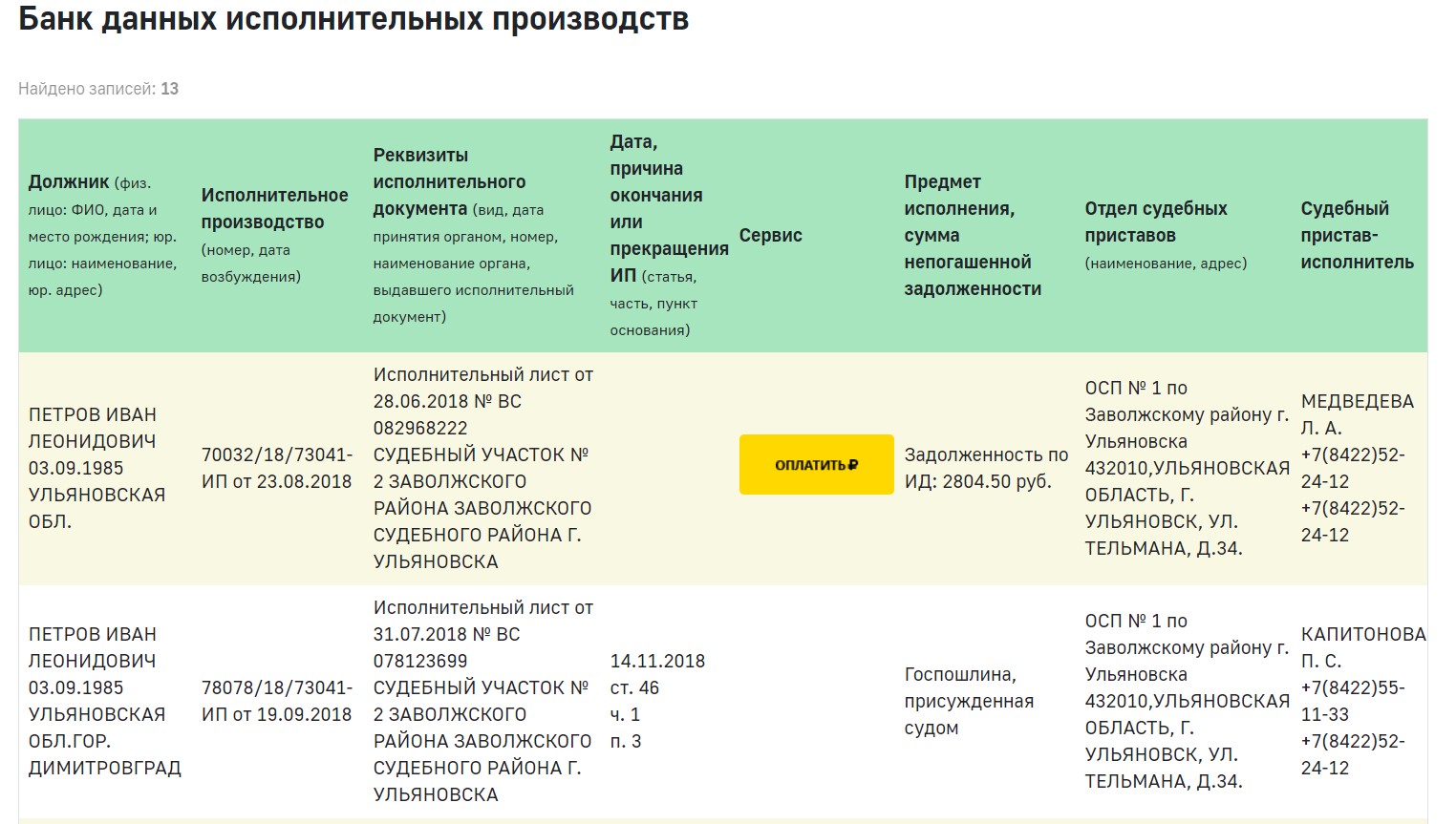
По ИНН можно пробить человека на предмет наличия налоговой задолженности.
- с помощью сервиса официального сайта ФНС России «Личный кабинет налогоплательщика для физических лиц»;
- на едином портале госуслуг в разделе «Узнай свою задолженность»
Проверить наличие информации в Банке данных исполнительных производств Федеральной службы судебных приставов.
Мобильный номер телефона человека.
Он позволяет узнать данный гражданина посредством осуществления «пробного» платежа через онлайн сервисы банков. Если осуществить поиск по номеру, ввести сумму и попробовать довести операцию до конца, пользователь узнает, кому принадлежит номер и есть ли у человека карта в данном банке.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Список полезной литературы
- Учимся проектированию Entity Relationship — диаграмм // Хабр URL: https://habr.com/ru/post/440556/ (дата обращения: 02.01.2021).
- Технологии баз данных. Лекция 3. Модель «Сущность-связь». URL: https://docplayer.ru/27886777-Model-sushchnost-svyaz-tehnologii-baz-dannyh-lekciya-3.html (дата обращения: 02.01.2021).
- Entity Relationship Diagram. URL: https://plantuml.com/ru/ie-diagram (дата обращения: 03.01.2021).
- Transact-SQL Reference (Database Engine) // Microsoft Docs URL: https://docs.microsoft.com/ru-ru/sql/t-sql/language-reference?view=sql-server-ver15 (дата обращения: 05.01.2021).
- Нормализация отношений. Шесть нормальных форм // Хабр URL: https://habr.com/ru/post/254773/ (дата обращения: 05.01.2021).
- Материалы для скачивания по SQL Server // Microsoft URL: https://www.microsoft.com/ru-ru/sql-server/sql-server-downloads (дата обращения: 05.01.2021).
- Другой пример проектирования базы данных (MySQL). URL: https://pro-prof.com/forums/topic/db_example
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
Преимущества проверки человека через онлайн сервис Чеклик
Если вы все еще не знаете, как пробить человека по базам данных, на помощь придет онлайн сервис Чеклик.
Наши преимущества:
- Круглосуточная онлайн поддержка;
- Работа только по официальной базе данных
- Возможность получения всех данных на одном ресурсе;
- Оптимальная стоимость услуг, которую можно выбрать в зависимости от предоставляемых сведений о людях
- Гарантия возврата денежных средств при наличии в отчете необъективной информации.
Алгоритм работы с сервисом следующий:
- Необходимо завести личный кабинет и заполнить необходимые поля;
- После выбора тарифа, нажать кнопку «Проверить», и система переместит вас в форму поиска;
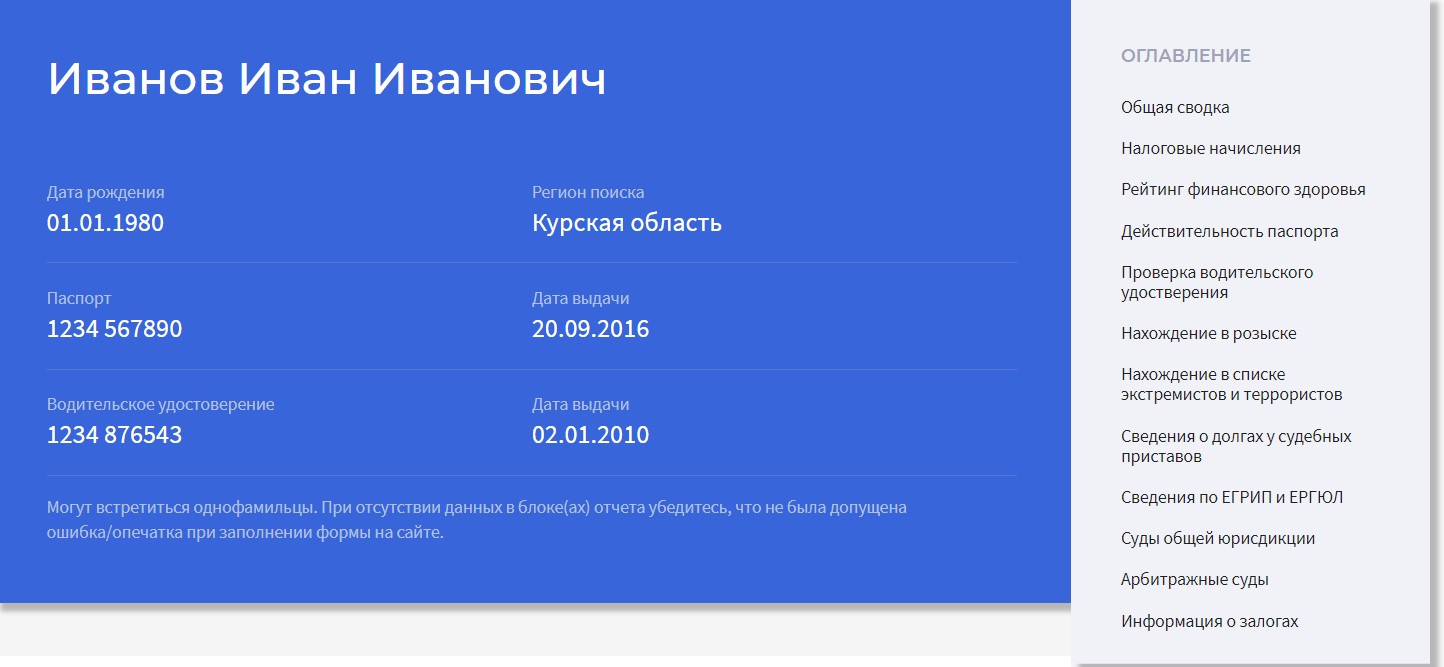
- Заполняем ФИО, дату рождения и регион поиска; при наличии и для более точного, быстрого поиска можно ввести реквизиты паспорта или водительского удостоверения;
- Далее сервис сформирует отчет и отправит его на электронную почту и в личный кабинет пользователя.
При необходимости вы можете воспользоваться мобильным приложением Чеклик, которое скачивается на телефон и удобно в использовании.
Вам также может быть интересно
Пробить человека по базе данных

Проверка паспорта на действительность

Как проверить инн физического лица?
Планы на будущее
Во фреймворке заложены основные возможности, которые я хотел в нем видеть. Он вполне работоспособен, но тем не менее ту стадию, на которой он находится в данный момент, я бы назвал только концептом.
Так, например, на данный момент существует backend, который позволяет фреймворку работать только с базой данных MySQL, из-за чего его можно запустить только на Electron. Также не реализован интерфейс для работы на мобильных устройствах и ряд других возможностей.
Ближайшие планы по развитию фреймворка:
- Реализовать механизмы объединения и группировок в запросах в классе Query.
- Добавить элементы управления для работы с объединениями и группировками.
- Разработать backend для преобразования объекта Query в json или xml, а также разработать серверную часть для работы с моделями Django.
- Реализовать механизм кеширования запросов к серверу данных.
- Воплотить в жизнь большое количество других идей.
Общая система типов
Важной особенностью работы с базой данных является то, что в «1С:Предприятии 8» реализована общая система типов языка и полей баз данных. Иными словами, разработчик одинаковым образом определяет поля базы данных и переменные встроенного языка и одинаковым образом работает с ними.. Этим система «1С:Предприятие 8» выгодно отличается от универсальных инструментальных средств
Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Этим система «1С:Предприятие 8» выгодно отличается от универсальных инструментальных средств. Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Модели и работа с данными
Особенностью фреймворка, в отличие от того же Django, является то, что для описания списков записей и самих записей используются разные типы моделей: ListModel и RecordModel. Такой подход позволяет в списках отображать записи не только от одной, но и от разных моделей, а также нередактируемые строки (являющиеся, например, результатом работы над этими записями).
Хоть фреймворк и содержит необходимые для этого механизмы, описывать модели при разработке приложения не требуется. Модуль backend автоматически формирует внутренние модели на основании тех, которые уже существуют и описаны в других средах (таких как Django, Sequelize, SQL и иные).
У фреймворка есть сходства работы с Django. Например, классы для работы с выборками и запросами (QuerySet и Query) являются эквивалентами одноименных классов Django, адаптированными из кода Python в код TypeScript. Например, для выборки данных из источника данных необходимо написать примерно следующий код:
Ещё одна отличительная особенность фреймворка — поддержка виртуальных полей. Когда изменяется виртуальное поле, оно может менять реальные поля объектов, а когда меняются значения реальных полей, могут изменяться и виртуальные. Что-то похожее есть и в Django, когда через объект мы имеем доступ к данным, не хранящимся в базе данных в том виде, в котором они доступны в этом объекте,— это получение ссылающихся на объект других объектов через свойство xxxxxx_set либо получение доступа к объекту через свойство, когда в базе данных хранится лишь id этого объекта.
На иллюстрации ниже поля product_id и product_name — реальные, а поле product — виртуальное.
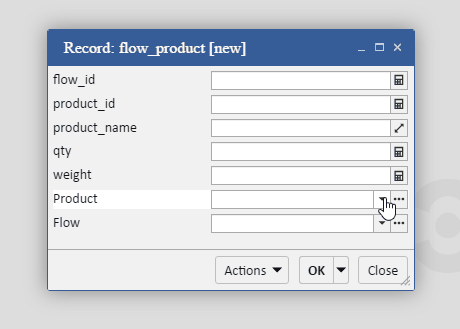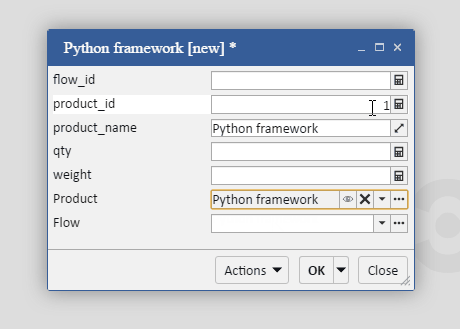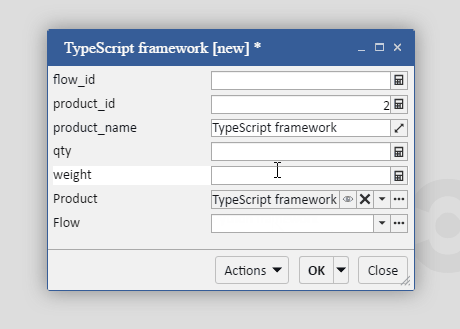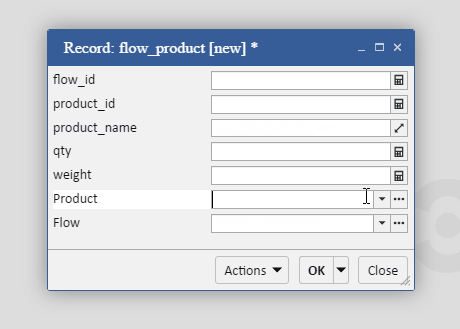
Во фреймворке реализована «ленивая загрузка зависимых записей». В отличие от Django, здесь разработчик может решать, в каких случаях этот механизм лучше не применять, а получать данные сразу, тем самым уменьшая количество запросов между клиентом и сервером. Так, в примере выше у продукта product есть поле supplier, которое ссылается на поставщика. По-умолчанию, поставщики будут запрашиваться из базы данных только при обращении к полю product. Однако, если вышеприведенный пример модифицировать следующим образом: …getRows(‘supplier’).subscribe(products => {…}); — то каждый продукт из списка products уже будет содержать данные о поставщике и при обращении к ним не будет происходить запроса к базе данных.