Кей коллектор: инструкция по работе и настройке программы
Содержание:
- Переименование и цветовая маркировка
- Навигация по группам
- Кластеризация в Key Collector 4
- Как установить программу на компьютер
- Подбираем маски
- Сбор семантики
- Первичный сбор частотности ключевых фраз
- Процесс парсинга в Кей Коллекторе
- Главное меню программы
- Сбор семантики в Key Collector
- Настройки в зависимости от размера семантики
- Общая настройка Кей Коллектора
- Минусация
- Сбор частотностей
- Подбор ключевых слов с Key Collector
- Выводы
Переименование и цветовая маркировка
Для переименования группы дважды кликните по ее заголовку или воспользуйтесь соответствующим пунктом в контекстном меню.
Для массового редактирования заголовков можно воспользоваться функциями в меню «Формат заголовков» на вкладке «Управление группами».
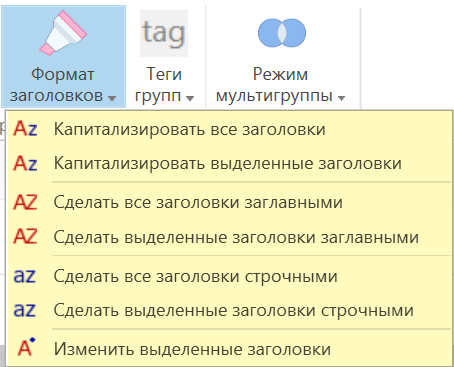
Вы также можете помечать цветами заголовки групп. Для пометки нескольких выделенных групп зажмите клавишу Ctrl.
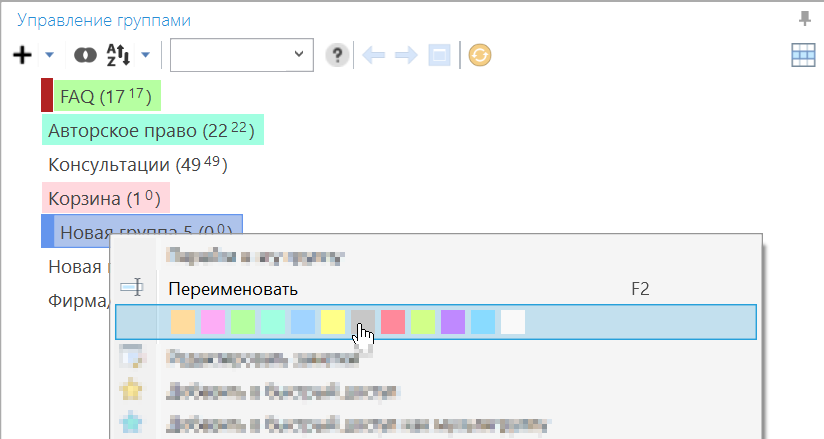
В «Настройках — Интерфейс — Управление группами» можно задать список цветов в формате цветов HTML (HEX ARGB).
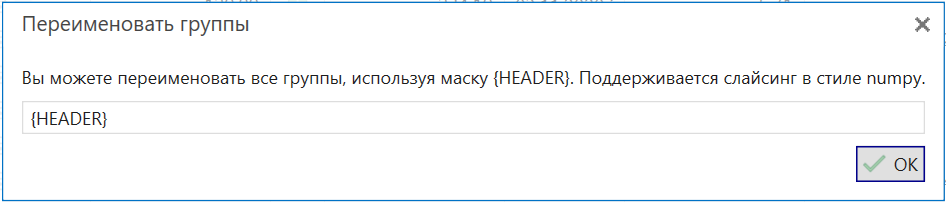
Массовое переименование групп по маске
Функция изменения выделенных групп позволяет массово изменить заголовки выделенных групп по заданному пользователем шаблону. Например, можно не только назначить нескольким группам новый единый заголовок, но и сохранить в нем значения прошлых заголовков.
Группы «кастрюли», «сковородки», «чашки» могут быть переименованы в «кастрюли Москва», «сковородки Москва», «чашки Москва» (в существующему заголовку добавлено слово «Москва»). Или же можно выполнить замену части заголовка: «кабель 2.5», «провод 2.5» на «кабель 1.75», «провод 1.75» (выполнена замена 2.5 на 1.75).
Простые замены
Простая замена может использовать в маске макрос {HEADER}, который вставит на место {HEADER} прошлое значение заголовка группы.
Например, маска «купить {HEADER} Москва» превратит группы «носки», «колготки» в «купить носки Москва», «купить колготки Москва».
Слайсинг в стиле numpy
Помимо простой замены с сохранением полного прошлого заголовка иногда требуется модифицировать прошлый заголовок: отрезать какую-то его часть с начали или конца, использовать какую-то информацию из середины и т.п.
Для этих нужд используется широко известный синтаксис слайсинга в numpy (библиотека Python), поэтому если вы его освоите, то это пригодится не только при работе с Key Collector, но и для решения других задач.
Вы можете извлекать наборы символов (подстроки), задавая границы и длину строк с начала или с конца. Приведем несколько примеров.
Отрезать начало строки — {HEADER}N:
Можно указать индекс начала строки N с начала или с конца.
- {HEADER}4: — взять подстроку, начиная с 4-го символа с начала и до конца
- мск интернет —> интернет
- {HEADER}-5: — взять подстроку, начиная с 5-го символа с конца и до конца
-
блин 25 кг
—> 25 кг
Отрезать конец строки — {HEADER}:M
Можно указать индекс конца строки M с начала или с конца.
- {HEADER}:8 — взять подстроку, начиная с начала и до 8-го символа
- интернет мск —> интернет
- {HEADER}:-6 — взять подстроку, начиная с начала и заканчивая 6-м символом с конца
- саженцы москва —> саженцы
Взять из середины строки — {HEADER}N:M
Здесь можно указать индекс начала N и конца M подстроки. Аналогично можно указывать индексацию с начала или с конца строки, но индекс конца M должен быть расположен в абсолютном значении дальше индекса начала N.
- {HEADER}4:6 — взять подстроку, начиная с 4-го символа и заканчивая 6-м символом
- 122.65 частота —> 65
Функции замены
Поддерживается функция замены значения в заголовке на новое значение REPLACE(«old»;»new»). Использовать дополнительную индексацию или маску в параметрах функции не допускается (т.е. в кавычках должны быть заданы обычные слова или части слов.
- REPLACE(«мск»;»спб») — заменить в заголовке «мск» на «спб»
- ворота мск —> ворота спб
Также поддерживается расширенная функция замены по регулярному выражению REPLACERG(«pattern»;»replacement»). Опытные пользователи могут выполнять более сложные замены, используя синтаксис регулярных выражений.
Навигация по группам
При работе со сложными структурами иногда хочется сконцентрировать внимание на каком-нибудь одном разделе проекта. Для перехода внутрь структуры вызовите контекстное меню к интересующей родительской группе и выберите пункт «Перейти в эту группу»
Для перехода внутрь структуры вызовите контекстное меню к интересующей родительской группе и выберите пункт «Перейти в эту группу».
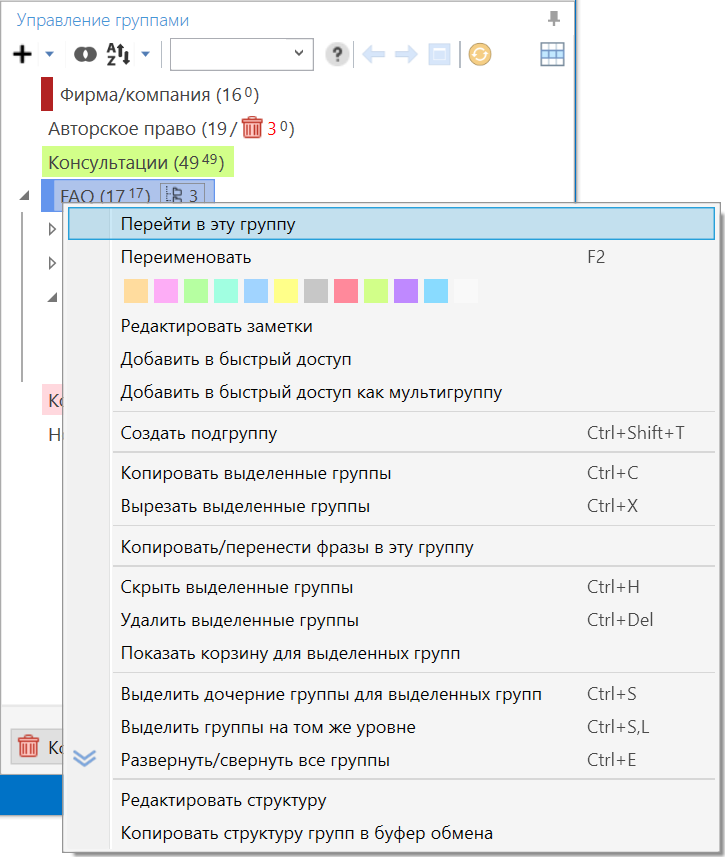
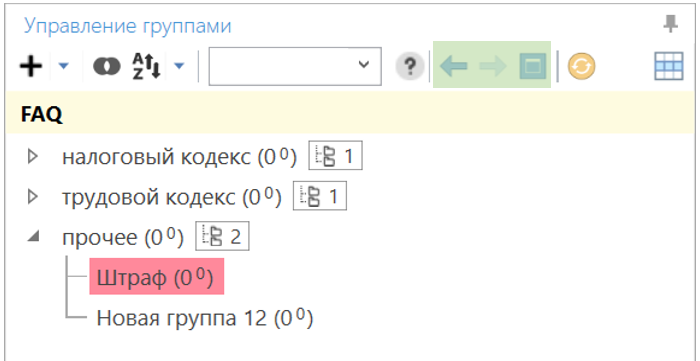
С этого момента дерево будет содержать только дочерние узлы выбранной родительской группы. При этом вы можете перейти глубже по структуре или же вернуться назад (для навигации воспользуйтесь кнопками в панели инструментов над списком групп).
Переход в группу — это навигационная операция в панели групп, которая не влияет на отображаемые фразы в таблице. Для отображения фраз какой-либо группы дополнительно потребуется выбрать нужную группу в панели.
Переключение между последними активными группами
Часто возникает необходимость попеременно просматривать содержимое то одной, то другой группы или же требуется вернуться к ранее загруженной мультигруппе с заданными условиями сортировки и фильтрации.
Для этого предусмотрена функция перехода назад и вперед в контекстном меню панели управления группами (вызывать его требуется не на заголовке группы, а на свободной области панели).

В отличие от навигационного «перехода в группу» речь идет о переключении отображаемого в таблице содержимого группы.
Кластеризация в Key Collector 4
1. Для кластеризации нам нужно собрать данные по SERP. Переходим во вкладку Парсинг — Поисковая выдача — “Собрать данные из ПС Яндекс”
2. Когда данные по SERP будут спаршены. Переходим во вкладку данные — “Анализ групп” по поисковой выдачи v3.
В колонке “Сумма” выбираем точную частотность. Режим группировки “Пересечение”. Сила группировки 4, размер группы 3. Также ставим галочки напротив всех настроек. Нажимаем “Начать анализ”.

3. По завершению анализа у нас есть готовая кластеризация. Благодаря данным SERP. Кейколлектор сгруппировал запросы. Теперь их нужно пересмотреть на предмет интента и пересечения в выдачи. А потом создать структуру.
Вот неплохой видео мануал по кластеризации в кей коллектор 4.
Да нужно потратить свое время, чтобы изучить данный софт. Да нужно купить расходники в виде прокси и капчи. Но зато нет ежемесячной подписки. А когда вам нужно собрать или кластеризовать семантику, вам это легко сделаете здесь и сейчас, без регистрации и смс*
Структура для сайта
Благодаря группировке у меня появилась структура для страницы Услуг: “Курсовая работа”. Теперь можно писать ТЗ для копирайтеров. Хотя скорее всего, тексты я буду писать сам.
Доброго времени и спасибо за внимание!
Как установить программу на компьютер
Оплатите и скачайте программу на официальном сайте. Цена одной лицензии 1 800 рублей.

Запустите установочный файл скачанной программы и следуйте инструкции.
После установки нужно активировать лицензию:
- При запуске установленной программы появится окно с уникальным идентификатором (HID).
- Лицензия (файл lic.license) придет на почтовый ящик после оплаты, ее нужно положить в папку с программой. По умолчанию Кей Коллектор устанавливается в «Мои документы/Key Collector».
- Можно запускать программу и пользоваться.
Если возникли трудности, ищите всю информацию по инсталляции на сайте программы.
Подбираем маски
Пробиваем маски через Wordstat и ищем похожие запросы.
Пример: собираем РК для бокс-клуба. Наши маски: «записаться на бокс», «занятия боксом» и т. д. Само слово «бокс» слишком широкое по смыслу. Включить его в нашу РК даже в точном соответствии нельзя. Но мы можем пробить слово «бокс» (уточнённое высокочастотными минус-словами) через Wordstat и найти ещё несколько масок, например, «абонемент на бокс», «тренера по боксу» и т. п.
Замеряем пульс российского диджитал-консалтинга
Какие консалтинговые услуги востребованы на российском рынке, и как они меняют бизнес-процессы? Представляете компанию-заказчика диджитал-услуг?
Примите участие в исследовании Convergent, Ruward и Cossa!
Кроме того
-
Изучайте отчёты по реальным поисковым фразам в «Яндекс.Метрике» и Google AdWords.
-
Используйте сервисы подбора синонимов.
-
Пользуйтесь формулами сцепки в Excel или сервисами перемножения. Excel позволяет рассортировать все полученные маски «по полочкам», точнее, по столбикам. Сервис перемножения, наоборот, формирует единый столбец. Что удобнее — зависит от ситуации.
-
Используйте минус-слова уже на уровне масок для уточнения запросов. Например, мы собираем ядро для шкафов, предназначенных для разных помещений. Очевидные маски: «Шкаф гостиная», «Шкаф прихожая» и т. д. Но также можно пробить «Шкаф -духовой -холодильный» — этими минусами мы отсеем половину мусора уже на входе.
-
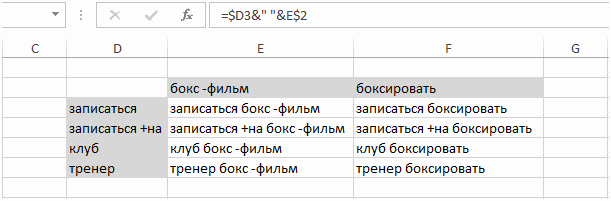
Пользуйтесь операторами «+» и «!», чтобы вытянуть большее количество слов из Wordstat. (Знак «!» фиксирует падеж и число слова, а «+» нужен для принудительного учёта предлогов и союзов.) По запросу с использованием операторов Wordstat выдаёт новую выборку, в которой могут оказаться и новые слова.
Пример: пробиваем маску «купить шкаф». Wordstat выдаёт фразы со следующей частотностью:
-
«купить шкаф» (100 000 показов);
-
«купить шкаф москва» (50 000 показов);
-
«купить шкаф недорого» (10 000 показов).
-
…
Далее пробиваем маску «Купить шкаф +в» — и тут Wordstat выдаёт новую картинку:
-
«купить шкаф +в» (70 000 показов);
-
«купить шкаф +в спальню» (40 000) показов;
-
…
Во вторую выборку попал запрос «купить шкаф +в спальню» (40 000 показов). Это вложенная фраза для «Купить шкаф». Судя по количеству показов, она должна оказаться в первой выборке между фразами «Купить шкаф москва» (50 000) и «Купить шкаф недорого» (10 000), но её там нет.
Сбор семантики
Вот мы и перешли к самому вкусному. Собирать ключи можно из левой и правой колонок Вордстата. Как вы наверняка знаете, в левой показываются запросы с вхождением ключевого слова. В правой же – похожие запросы.

В этом материале мы рассмотрим именно сбор из левой колонки. Итак, нажимаем на красную иконку, после чего у нас открывается такое окно.
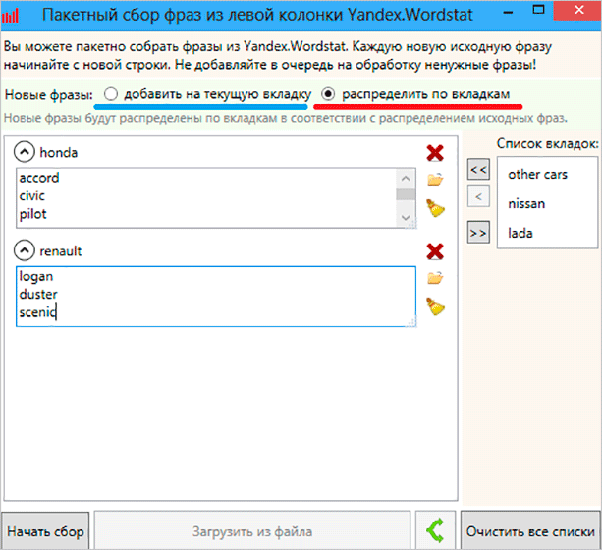
Здесь мы можем ввести все ключевые слова, которые нам нужны. Их можно разбить на вкладки и группы. Ключи можно вводить вручную, а можно просто выгрузить из файла.
После нажатия кнопки “Начать сбор” программа начнет свою работу. В зависимости от настроек и количества ключей этот процесс может занять определенное время. Иногда и по несколько часов. В конечном итоге вы получите список всех ключевых слов и фраз из левой колонки Вордстата.
Далее мы можем снять более точную частотность, потому как та, что будет доступна сразу после сбора, – ложная. Не стоит ей доверять и уж тем более делать какие-то выводы.
При сборе из правой колонки порядок действий тот же самый. Только ключей получится больше, в силу того, что в таблицу попадут все “похожие”.
Частотность
После сбора самой семантики, вы можете собрать частотность. Причем базовая частотность не даст нам особо полезной информации, поэтому нас интересует частотности с вхождением конкретных слов (“ “) и с точным вхождением (“!”)
Для сбора всех видов частотностей мы можем использовать одну кнопку.
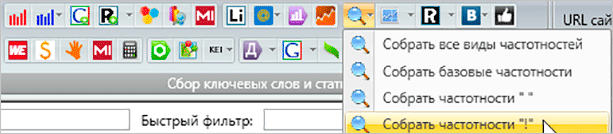
Съем более точных частотностей позволит вам получить наиболее правильные статистические данные о количестве запросов в Яндексе. Базовая вариация не отражает истинную суть, и чаще всего при составлении семантического ядра она игнорируется.
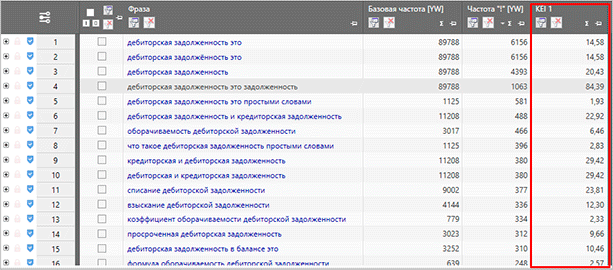
Именно сбор частотности в конечном итоге позволяет вам кластеризовать семантическое ядро по запросам: ВЧ, СЧ и НЧ. Исходя из этих данных, сеошники могут разделять ключи по группам, создавая для каждой отдельной статьи свою небольшую базу из тайтла и нескольких ключевых слов. Далее эта информация передается копирайтерам для написания статей. Сейчас такой способ является наиболее популярным при работе с информационными сайтами.
Сезонность
Сезонные запросы – это ключи, которые актуальны в какое-то время года или в какое-то конкретное время. Если вы собираете семантику для магазина с пляжными товарами, то вам нужно брать в расчет наибольший спрос, а именно в летнее время.
Сбор сезонности позволит вам определить, какие запросы в какое время пользуются наибольшей популярностью. Чтобы собрать эту информацию с помощью Кей Коллектора, найдите в меню иконок кнопку “Сбор ключевых слов и статистики”.
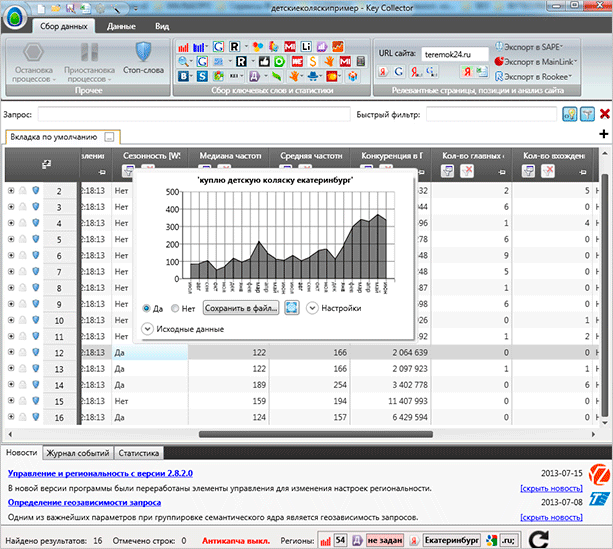
После завершения процесса на примере графика вы сможете увидеть популярность того или иного запроса в какой-то конкретный месяц.
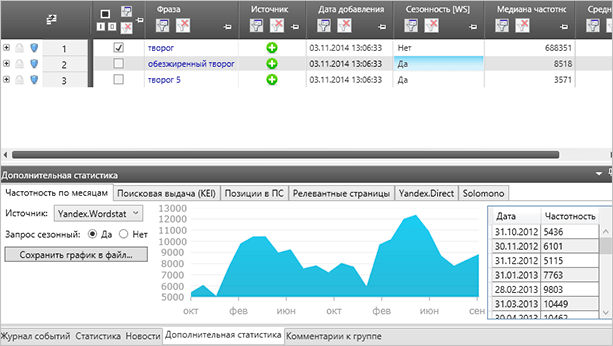
Вы можете получить данные по неделям, а не по месяцам, как это представлено на скриншоте. Для настройки используйте все ту же кнопку “Сбор ключевых слов и статистики”, она раскрывается, там вы и найдете соответствующий пункт.
При необходимости вы можете посмотреть более подробную информацию. Для этого просто кликните на нужной ячейке.
Первичный сбор частотности ключевых фраз
Вернемся к нашей карте мыслей и нашим пересечениям запросов.
Сейчас требуется скопировать все пересечения и добавить их в key collector.
Для этого создаем новый проект.

Создание проекта в Кей Коллектор
В открывшемся окне переходим во вкладку «Сбор данных» и нажимаем на кнопку «Добавить фразы»
Вставляем полученные фразы при пересечении запросов из карты мыслей.
Жмём кнопку «Добавить в таблицу»

Добавление ключевых фраз в Key Collector
Нажимаем на значок директа (Сбор статистики Яндекс Директ)
В открывшемся окне задаем требуемый регион.
Проверяем наличие галочки в пункте «Целью запуска сбора статистики является заполнение колонок частот Yandex.Wordstat»
И нажимаем получить данные.

Настройки сбора частотности через Яндекс Директ
Первичный сбор статистики производить лучше именнотаким образом, так как этот метод гораздо быстрее, чем сбор статистики с помощью только одного wordstat.
Для увеличения скорости сбора семантического ядра, изначально требуется отбросить заведомо пустые запросы, чтобы лишний раз не обращаться к серверу яндекс вордстат при парсинге, что существенно экономит время.
На скриншоте с Журнала событий Key Collector отчетливо видно, что сбор занял всего минуту при 1 аккаунте. Было проверено 42 слова и большую часть из этого времени заняла авторизация.

Скорость сбора статистики в Кей Коллектор
После сбора статистики в столбце «Базовая частота » появится число отражающие количество запросов в заданном регионе за месяц.
Далее требуется отсечь те слова, у которых по этой статистике 0 запросов.
Для этого их надо отфильтровать, нажимаем на значок воронки (фильтр) рядом с названием столбца.
В открывшемся окне, выбираем условие отображения «Больше» 0.
И нажимаем «Применить».

Настройки фильтра в Key Collector
Перед нами все фразы с частотность больше нуля.
Скопируем их.
Для этого правой клавишей мыши щелкаем по названию столбца и жмем «Скопировать колонку в буфер обмена»

Копирование слов из Key Collector
Готово! Теперь можно перейти к самому важному — Парсингу.
Парсинг запросов
Первым делом создаем новую папку, комбинацией shift+t или нажатием на значок плюса в меню с группами.

Новая папка для парсинга
Для добавления скопированных ранее слов в парсинг, нажимаем на «Пакетный Сбор слов из левой колонки Yandex.Wordstat» (Красный значок статистики).
Проверяем, что не установлено отслеживание повторов.

Парсинг запросов из левой колонки Wordstat
Вставляем слова в открывшееся окно и нажимаем кнопку «Начать сбор»

Парсинг в Key Collector.png
Вот и всё, ждем окончания парсинга и продолжаем работа.
После сбора семантического ядра потребуется разгруппировать и отобрать минус слова.
Процесс парсинга в Кей Коллекторе
Сам процесс достаточно прост и не является чем-то сложным и выполняется в автоматическом режиме.
Первоначально нужно сразу же выставить нужное гео для парсинга, это делается в самом низу программы:
После этого нужно создать папки, куда будут помещаться спарсенные ключевые слова, папки создаются в левой колонке программы. Конечно можно парсить все в одну папку и потом делать группировку ключей, но логичнее и удобнее заранее поделить маски ключей по смыслу и парсить маски по папкам. Например: есть две маски ключей, которые хотим спарсить — вызов такси и заказать такси, для удобства дальнейшей работы с ключами, парсим маски не в общую папку, а в соответствующие две папки, чтобы ключи уже были отсортированы.
Кроме этого, если масок не много, то можно каждую папку назвать маской и тогда программа сделает парсинг по названию папки, что является очень удобным функционалом.
Для этого заранее создаем нужные папки и нажимаем на парсинг с вордстата. По умолчанию стоит галочка «Добавить в текущую группу», но нужно поставить галочку «Распределить по группам» и нажать на красную стрелочку, как показано на картинке. Здесь можно в каждую папку поместить нужные маски (т.е. не каждую маску парсить отдельно, а чтобы в одной папке были распарсено сразу несколько масок ключей); можно убрать не нужные папки и стоит заметить, что названия папок тоже будут распарсены (если этого вам не нужно просто убираем не нужное ключевое слово). Далее нажимаем на «Начать сбор» и происходит парсинг, после которого идет следующая работа — сбор минус слов, чистка ключей и их группировка:

Главное меню программы
Для того, чтобы попасть в меню нам нужно в верхнем правом углу выбрать “Файл”.

Добро пожаловать в Key Collector!
В появившемся меню вы можете создать новый файл или открыть уже ранее существующий проект, импортировать данные из другого проекта или файла в формате CSV.
Загрузка проекта
Меню быстрого доступа
Используя меню быстрого доступа вы можете добавить наиболее часто используемые кнопки.
Меню быстрого доступа
Для добавления новых элементов нужно правой кнопкой мышки нажать на интересующий значок. После чего в появившемся окне выбрать пункт “Добавить в панель быстрого доступа”
Добавить в палень быстрого доступа
Теперь данный элемент будет добавлен в меню. Если вы захотите удалить кнопку из меню быстрого доступа, тогда проделайте аналогичные действия: нажмите правой кнопкой мышки на иконку и дальше в меню выберите “Удалить с панели быстрого доступа”.
Удалить с панели быстрого доступа
Основная рабочая область
Основную рабочую область используют для отображения пользовательских групп и экрана приветствия после запуска программы. В ней вы можете ознакомиться со свежими новостям относительно программы, увидеть статистику хода выполнения работы и т.д.
Область новостей, журнала событий и статистика

Область новостей, журнала событий и статистика
Данная вкладка предназначена для:
-
Отображения журнала событий.
-
Получения последних новостей программы.
-
Просмотра статистики по текущему выполнению задач.
-
Просмотра дополнительных данных статистики: отображение списка релевантных страниц, графиков истории позиций, сезонности, поисковой выдачи и тд.
Под просмотром дополнительной статистики имеется в виду просмотр тех данных, которые не могут быть показаны в стандартных таблицах и выводятся для каждой фразы в отдельности. К дополнительной статистике принадлежит:
-
Просмотр количества акноров с помощью сервиса Solomono. Используем кнопку “Количество анкоров Solomono”.
-
Просмотр с помощью графика или в виде таблицы истории позиций. Для этого нажимаем “Позиция Yandex” и “Позиция Google”.
-
Просмотр состава поисковой выдачи по какому-либо запросу: адреса страниц, заголовки, сниппеты. Для этого используем «Кол-во вхождений в заголовок «, «Кол-во вхождений в заголовок » и «Кол-во вхождений в заголовок «.
-
Просмотр релевантных страниц — колонки «Рел. страница » и «Рел. страница «.
-
Просмотр частотности слов по месяцам для Google Adwors — колонка «Частотность (регионы) »
-
Просмотр частотности для Yandex Wordstats по неделям и месяцам. Для этого переходим в раздел «Сезонность «.
Для того, чтобы увидеть данную статистику надо выбрать нужную фразу и перейти во вкладку “Дополнительная статистика”. В этом меню будет доступна интересующая подвкладка с дополнительной статистикой.
Отображение вкладок можно настроить на свое усмотрение. Для этого надо зажать левую кнопку мышки на заголовок с вкладкой и перетащить в нужную сторону.

Отображение вкладок
Панель состояния
Панель состояния нужна для показа информации о количестве отмеченных строк и информацию об использовании автоматической капчи.

Панель состояния
Выше выделена кнопка принудительного обновления содержимого активной таблицы.
Сбор семантики в Key Collector
На примере группы запросов: “курсовая работа”, я покажу как я собираю семантику для своего сайта, с помощью кейколлектора.
1. Устанавливаем расширение для браузера “Serpstat Website SEO Checker”
3. Активируем расширение, и переходим во вкладку “Анализ страницы”. Там мы получаем ТОП-10 ключевых слов по URL. Копируем в ключевые слова в текстовый файл, удаляя лишнее.

4. Полученный список ключей переносим в текстовый файл.
5. Открываем кейколлектор. Вкладка: “Данные” — Прочее — “Планировщик задач”. Далее нажимаеv на шестеренку “Задать параметры”.
Выбираем сбор фраз из Яндекс Вордстат. Выбираем регион, в моем случае это Россия. Далее нажимаем на значок “Распределить по группам” — загружаем список наших ключей — нажимаем “Применить изменения”.

6. Далее добавляем в скрипт задачу: “Собрать поисковые подсказки Яндекс” В настройках с помощью желтых и зеленых папок переносим наши фразы.
Потом добавляем в скрипт: “Собрать прогноз из Яндекс Директ”. В настройках выбираем все наши группы, выбираем нужный регион, ставим галочки напротив всех частот. Для полной семантики, можно добавить ПС Google.
7. Нажимаем “Создать скрипт”, пишем имя для скрипта и нажимаем “Продолжить”. Все, теперь ждем пока спарсятся все ключи.

8. После того как Key Collector закончит сбор фраз и частотность, нам нужно удалить все запросы равные нулю. Включаем мультигруппы: выделяем все наши группы Ctrl+A и нажимаем F3.
В колонке с точной частотность настраиваем фильтр: равно 0.
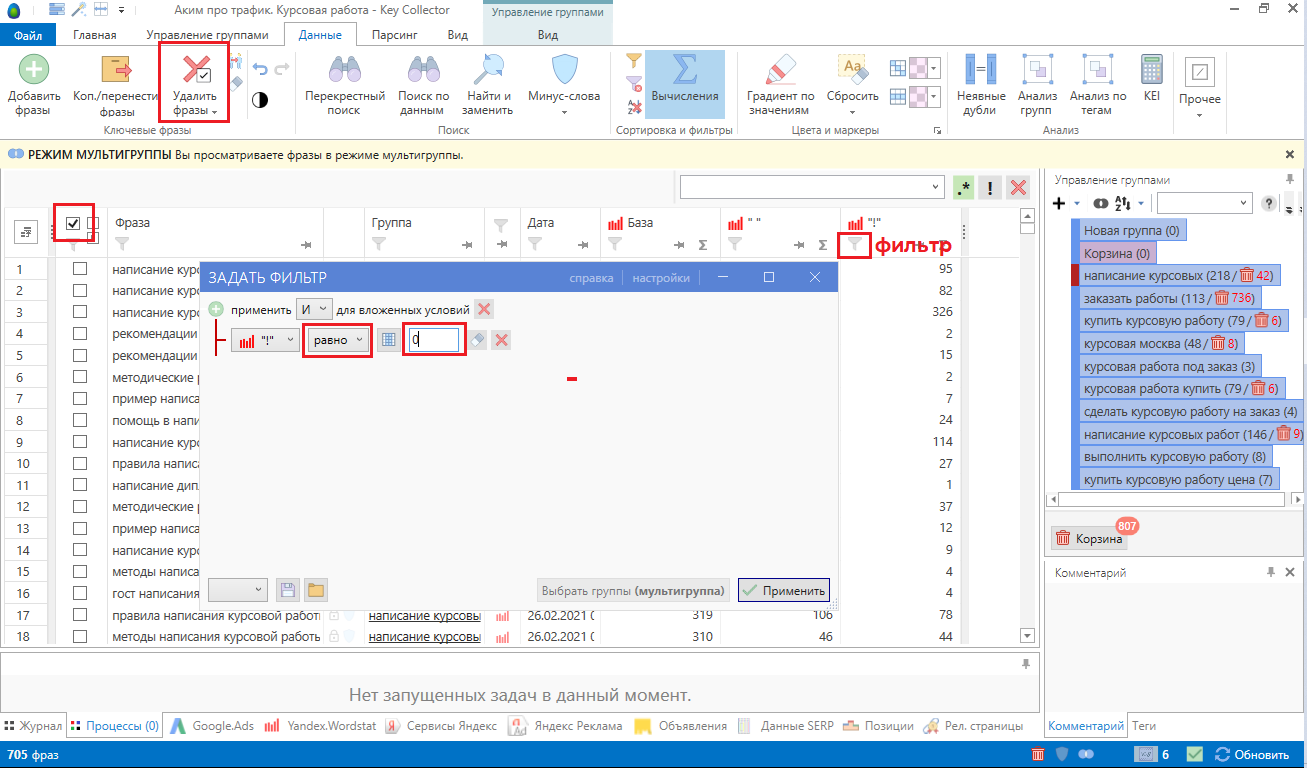
9. Собранную семантику нужно очистить на предмет дублей. Переходим во вкладку: Главная — «Неявные дубли» — Найти. С помощью умной отметки выбираем запросы, далее нажимаем удалить и применить.
10. Далее с помощью функции “Минус Слова” удалить ненужные запросы, типа скачать торрент, порно, итд.
11. Теперь все оставшиеся фразы нам нужно перенести в одну, новую группу.
Выделяем все наши группы Ctrl+A — Вкладка данные — Копировать/перенести фразы. Перенести в «Новая группа». После чего все остальные группы можно удалять. Новую группу переименовываем в «Курсовая работа». Теперь у нас есть пул запросов, и можно переходить на этап кластеризации.
Настройки в зависимости от размера семантики
Настройки для небольшой семантики (от 0 до 1 000 ключей).
Дальше все настройки зависят от того какая скорость сбора семантика вам требуется, если семантика небольшая, то и времени на ее парсинг уйдет немного.
Тогда можно обойтись добавлением одного (не основного!) аккаунта Яндекса для парсинга и можно приступать.
-
Выбираем пункт меню Yandex.Direct
-
Жмем кнопку «Добавить строку»
-
Вводим логин и пароль от аккаунта Яндекса
-
Нажимаем на кнопку пуск для проверки работоспособности аккаунта
И Жмем сохранить изменения
 Настройки Yandex Direct в Key Collector
Настройки Yandex Direct в Key Collector
Настройки для средних и больших семантик (более 1 000 ключей)Сначала теория
Для настройки парсинга средних или больших семантических ядер потребуется расширить количество потоков и соответственно количество аккаунтов Яндекс Директ для ускорения сбора ключевых фраз.
Принцип сбора заключается в том, что Key Collector используя добавленные в него аккаунты Яндекса, обращается к yandex wordstat и постранично копирует все выданные запросы по ключевой фразе (если страница полная, то запросов в левой колонке ровно 50)
далее уходит в ожидание на 25-30 секунд, для избежания бана аккаунта и после этого еще раз обращается уже к следующей странице, либо к следующей фразе. В итоге получается 100 запросов в минуту, не считая перехода на другое ключевое слово, т.е. примерно 6 000 запросов в час.
Следовательно, если требуется собрать большие семантики на 10 000 – 20 000 слов потребуется от 2 часов и более.
А если у вас сразу несколько тематик и количество ключевых фраз более 100 000? На их сбор уйдет слишком много времени.
Для увеличения скорости требуется увеличивать количество потоков, при этом скорость увеличивается ровно во столько раз сколько будет добавлено потоков.
Для этого потребуется равное количество Яндекс аккаунтов и готовых прокси серверов. Их можно приобрести на специальных площадках. В среднем, цена за один прокси + один аккаунт Яндекса — 100 рублей в месяц.
Мы используем 10 прокси и соответственно 10 аккаунтов Яндекса.
Это примерно 1 000 запросов в минуту.
Перейдем к настройке
Заходим в настройки Yandex.Wordstat и отключаем галочку напротив «Использовать основной Ip-адрес»
Здесь же выставляем количество потоков равное количеству доступных нам прокси и аккаунтов Яндекса.
Если вы приобрели 10 прокси и 8 Яндекс аккаунтов, то выставляйте 8 потоков, чтобы не повышать шансы блокировки Яндекс аккаунтов.

Настройка Yandex Wordstat в Key Collector
Для дальнейшей настройки переходим во вкладку Яндекс директ.
Жмем по кнопке добавить списком и вносим сюда все аккаунты по шаблону логин:пароль.

Настройки Яндекс Директ в Key Collector часть 1
После внесения списка аккаунтов требуется их проверить на работоспосоность:
-
Пролистываем настройки чуть ниже.
-
Нажимаем на зеленую кнопку запустить — все рабочие аккаунты отобразятся как зеленые, нерабочие красные.
-
Выставляем количество потоков
-
Снимаем галочку с использования основного ip-адреса.

Настройки Яндекс Директ в Key Collector
Переходим во вкладку «Сеть»
Вкладка Сеть настройки Key Collector
-
Здесь ставим галочку на пункте «Использовать прокси-серверы»
-
Далее нажимаем кнопку «Добавить из буфера»

Настройки Сети Key Collector
Копируем сюда прокси по шаблону адрес:порт@логин:пароль.

Настройка прокси кей коллектор
После добавления проверяем прокси также, как и с Яндекс директом, красные не рабочие, зеленые в полном порядке.
Нажимаем кнопку сохранить изменения.

Проверка прокси в кей коллектор
С настройками закончили. Данных настроек вполне хватит для сбора семантики и ее частотности. На свой страх и риск можно также протестировать настройки паузы между запросами для увеличения скорости сбора.
Общая настройка Кей Коллектора
Для работы с вордстатом понадобиться: здесь все просто, нужно отдельно зарегистрировать яндекс почту и создать там тестовую рекламную кампанию, можно с одним объявлением, можно просто черновую (без прохождения модерации и пополнения бюджета). В программе просто прописываем логин и пароль от почты и все работает.
Для работы с гугл планером понадобиться: зарегистрировать новый аккаунт в гугл адвордс. В обязательном порядке скачать последнюю версию браузера internet explorer и зайдя исключительно через данный браузер, также создать тестовую рекламную кампанию (без бюджета и активности). Главное заполнить все настройки пользователя — указать язык и местоположение. Фокус заключается в том, что без данных манипуляций, использовать гугл планер не получиться.
Переходим непосредственно к настройкам:

Заходим в настройки программы во вкладку Яндекс Вордстат», где выставляем следующие параметры:
— глубина парсинга — 0. Выставляя такое значение, вы будите получать обычный парсинг, но программа может автоматом парсить и в глубину, т.е. спарсив ключевые слова, она может парсить то, что уже спарсила, разбивая ключевые слова на более конкретные ключевые слова. Смысла глубокого парсинга нет, так как система будет парсить дубли, а не уникальные ключевые слова, и даже без глубокого парсинга мы все равно будем по нему показываться, так как используем основную маску. Если просто — глубокий парсинг делать не надо, выставляем значение ноль.
— парсить страницы, здесь выставляем стандартное значение — 40.
— добавлять в таблицу фразы с частотами от 1 до 99999999999. Здесь вы указываете какую частотность вы хотите видеть с парсенных ключевых слов. Есть директологи, которые не парсят все доскональна, а работают с ключевыми словами, которые имеют частотность от 10 и выше. Я же советую вам парсить все и начинать с 1. При таком подходе у вас будет самое полное семантическое ядро, а если вы решите, что такие ключевые слова вам не нужно, то уже после парсинга, можно при помощи фильтра выделить такие ключи и удалить.
— не снимать частоты для фраз меньше или равной 0. Логика проста, нам не нужно пустые ключевые слова, которые не будут приносить трафик, поэтому такие не ищем.
— количество потоков. Если вы используете одну почту от яндекс директа, то можете смело выставлять сразу 2 потока, и таким образом программа будет работать в два раза быстрее. И если вы не используете прокси сервера, то не убираем галочку «Использовать основной IP адрес».

Далее заходим во вкладку «Яндекс Директ», где указываем адреса свои электронных почт от яндекса и пароли от них. Достаточно указать 1-2 почты.

Во вкладке «Гугл Адвордс» указываем доступы от гугл адвордс (что логично).
Собственно, это все стандартные настройки, после которых заработает кей коллектор.
Минусация
Для того, чтобы очистить от ненужных слов собранные поисковые запросы потребуется:
Зайти во вкладку «Данные»
Нажимаем на кнопку «Анализ групп»

Анализ групп в Кей Коллектор
С помощью инструмента анализ групп можно быстро как разгруппировать, так и определить минус слова из собранных ключевых фраз.
Инструмент разбивает полученные ключевые фразы на отдельные слова и объединяет фразы в которых они присутствуют.
Разберем на примере:

Анализ групп в Key Collector
На скриншоте показан анализ групп по натяжным потолкам.
Напротив каждого слова проставлено количество фраз встречаемых с этим словом и суммарная их частотность.
Представим, что в дальнейшем нам потребуется создать кампанию на поиске.
Мы видим, что в верху списка есть слово фото, явно это свидетельствует о том, что человек ищет не рекламный запрос в поиске а именно фотографии с натяжными потолками. Напрямую по этому запросу рекламироваться нет особого смысла, а следовательно фото мы должны отправить к минус словам.

Минус слово в Key Collector
Для этого напротив слова ставим галочку и продолжаем поиск таких слов.
Когда запросов много советую сначала выстроить таблицу по частотности и отметить самые высокочастотные минус слова, дальше сортировать по алфавиту и пробежаться по всему списку, лучше пару раз.
После определения всех минус-слов, нажимаем правой кнопкой мыши по одному из отмеченных и выбираем пункт «Отправить 1-е слово из определений целиком отмеченных групп в окно стоп-слов»

Добавление фразы в окно стоп-слов
В открывшемся окне снимаем галочки с тех слов, которые попали сюда по ошибке. Советую снять галочки со всех слов и заново отметить те слова, которые требуется занести в минусы.
Жмем «Добавить в стоп-слова»

Окно стоп-слов в Кей коллектор
После добавления фраз в стоп-слова сворачиваем анализ групп.
Переходим во вкладку «Сбор данных», затем нажимаем на кнопку перенос фраз в другую группу и выбираем папку корзина.

Добавления фраз в корзину Key collector
Не удаляйте ненужные ключевые фразы, а перемещайте их в корзину, потом всегда можно запарсить новые слова с учетом уже собранных или же слова могут подойти для РСЯ.
Разгруппировка
Заключительным этапом перед экспортом работы в Key Collector будет разгруппировка ключевых фраз.
Для разгруппировки отлично подойдет карта мыслей, которую мы составляли в самом начале.
Легче всего начинать с общих названий услуг.
К примеру:
- Глянцевый
-
Матовый
Многоуровневый
- Тканевый
- Пвх
Дальше разгруппируйте еще более точней
- Глянцевый
- кухня
- ванная
- гостинная
- спальня
- Матовый
- кухня
- ванная
- гостиная
- спальня
И так далее, главное помнить, что в Яндексе статус «Мало показов» распространяется на группу объявлений и появляется при общей частотности группы меньше 20, из этого правила группируйте низкочастотные запросы с небольшим запасом на группу.
Для Google AdWords низкочастотные запросы не подойдут, так как там статус присваивается для ключевого слова, а не группы.
Для начала разгруппировки заходим в «Анализ Групп»
Отмечаем нужное нам слово галочкой и нажимаем правой кнопкой мыши по нему.
Выбираем пункт предпоследний пункт выпадающего меню.

Разгруппировка слов в Key Collector
В нашей группе автоматически создается новая папка с названием слова, которые мы выбрали и все слова, в которых это слово входило перенеслись в эту группу.
После разгруппировки основной группы переходим к тем, которые мы создали и также их дробим на подгруппы.
Таким образом, нам будет проще прописать текст объявлений в будущем.
По такому аналогу и распределяем на группы всё семантическое ядро.
В дальнейшем, названия этих папок будут служить нам как названия групп объявлений как в Директе так и в AdWords.
Сбор частотностей
После получения данных из Вордстата или других источников нужно собрать частотности, чтобы оценить спрос. На его основе будем делать группировку и составлять ТЗ.
Для этого есть 2 основных варианта.
- Можно собирать частотности с помощью кнопки «Сбор частотности из сервиса Yandex Wordstat». Это медленный вариант, он подходит для сбора частотностей фраз состоящих из 8 слов и более. В других случаях используйте следующий вариант.
- Лучше всего собирать частотность с помощью Yandex Direct. Программа будет обрабатывать слова не по одному, а целой пачкой зараз.
При сборе частотностей Директ можно указать, какие снимать и за какой период.
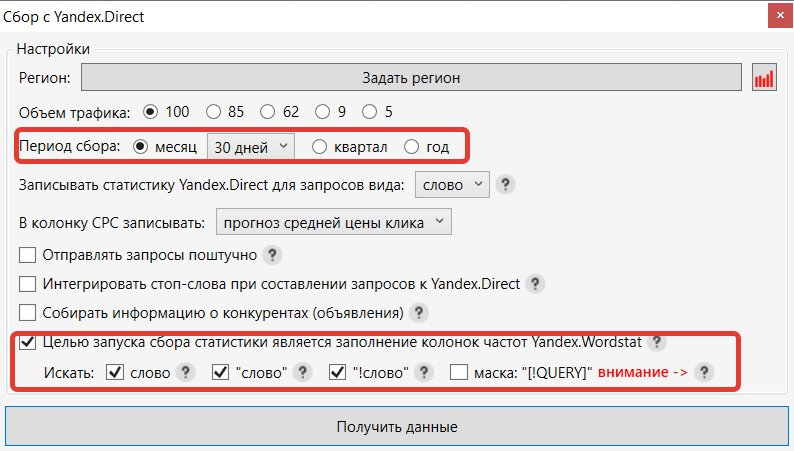
- Рекомендуется снимать частотности за последние 30 дней, если это не сезонные запросы. При съеме за другой период могут получиться не совсем адекватные цифры – видимо, Яндекс не хранит точные данные за более длительные периоды или выдает их в округленном виде.
- Съем фраз разных частотностей можно разбить на 2 или 3 этапа. Например, сначала снять базовую частотность (если добавлены запросы из других источников), отфильтровать по частотности и удалить запросы ниже определенного порога. Далее снять частотность в кавычках, снова отфильтровать запросы с неподходящей частотой и удалить их. И только потом снять самую точную частотность. Таким образом, процесс съема будет дешевле и быстрее.
Подбор ключевых слов с Key Collector
Наконец-то мы дошли до собственно подбора семантического ядра. В главном окне программы нажмите на большую кнопку «Новый проект«. Советую назвать файл проекта именем сайта, например, site.ru, и сохранить в специально созданную папку для проектов Key Collector, чтобы потом не тратить время на поиски.

В Коллекторе удобно сортировать ключевые слова по группам. Мне удобно, когда иерархия групп в проекте соответствует будущей структуре сайта, поэтому первая группа (группа по умолчанию) у меня соответствует главной странице сайта.

Для примера поработаем с тематикой «создание сайтов Москва». Начнём с Яндекса.
Сначала нужно задать регион:

Теперь нужно открыть «Пакетный сбор слов из левой колонки Yandex.Wordstat» и в возникшем окне ввести штук 5 наиболее очевидных в данной тематике ключевых фраз (на их основе будет производиться парсинг).

Теперь нужно нажать на кнопку «Начать сбор«.
Всё, можно пойти заварить кофе или переключиться на другие задачи. Кей Коллектору потребуется некоторое время, чтобы спарсить ключевые фразы.
В результате отобразится примерно следующее:

Выводы
Мы разобрали базовые настройки Key Collector (то, без чего невозможно начать работать). Также мы рассмотрели самые простые (и основные) примеры использования программы. И подобрали простенькое семантическое ядро, используя статистику Яндекс.Вордстат и Google AdWords.
Как вы понимаете, в статье показано примерно 20% от всех возможностей программы. Чтобы освоить Key Collector, нужно потратить несколько часов и изучить официальный мануал. Но оно того стоит.
Если после этой статьи вы решили, что проще заказать семантическое ядро у специалистов, чем разбираться самому, напишите мне через страницу Контакты, и мы обсудим детали.
И бонусное видео: чувак по имени Derek Brown виртуозно играет на саксофоне. Я даже побывал на его концерте во время джаз-фестиваля, это реально круто.