Своя субд за 3 недели. нужно всего лишь каждый день немного времени…
Содержание:
- Колоночные
- MySQL
- 1 — Поднимаем базу данных PostgreSQL в Docker-контейнере
- Что нужно, для того чтобы создать базу данных в Microsoft SQL Server?
- Общая система типов
- Создание пользователя с использованием SSMS
- Достоинства реляционных баз
- PostgreSQL
- Создание таблиц и ключей с помощью конструктор таблиц
- 10 — Резюме
- Удаление базы данных в Microsoft SQL Server
- Что такое схемы базы данных?
- MySQL Создание базы данных, используя MySQLi и PDO
- Достоинства документных баз
- Типы движков баз данных MySQL
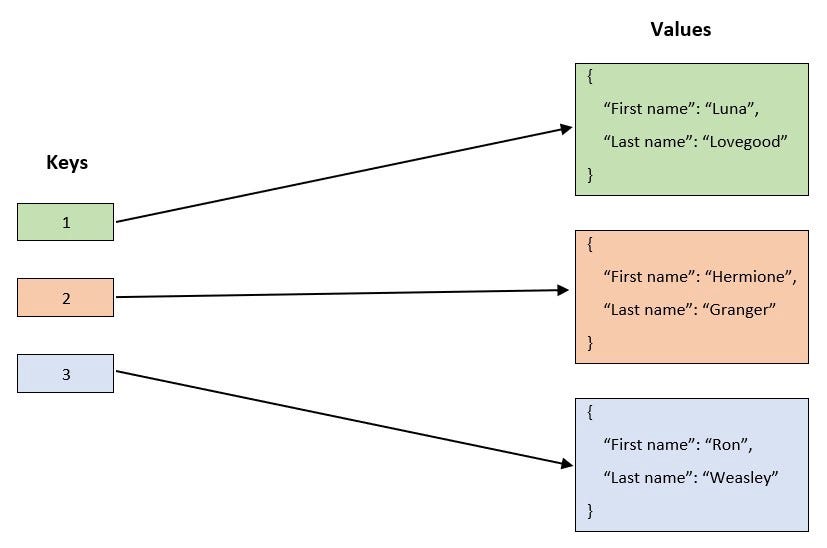
- Ключ-значение
- Объектный / табличный доступ к данным
- 8 — Alembic: добавляем взаимодействие с базой данных
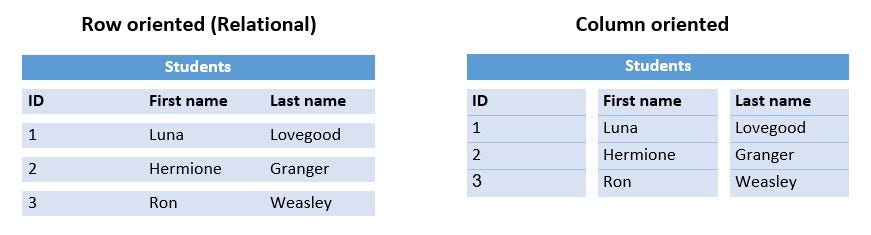
Колоночные
Атомарная единица таких БД — колонка таблицы. Данные сохраняются столбец за столбцом, что делает колоночные запросы очень эффективными, и, поскольку данные в каждой колонке однородны, это позволяет лучше сжимать данные.
Использование
В тех случаях, когда удобно делать запросы к подмножеству столбцов (оно не обязательно должно быть одинаковым каждый раз!). Колоночные БД обрабатывают такие запросы очень быстро, так как читают только конкретные колонки (в то время как строчные БД должны читать строки полностью).
В науке о данных часто бывает, что каждая колонка представляет определенную характеристику. Как специалист по данным я часто тренирую свои модели на подмножествах характеристик и проверяю отношения между ними и оценками (корреляция, дисперсия, значимость). То же подходит и для логов— в них зачастую множество полей, но при каждом запросе используются только некоторые. Например:
Cassandra.
Строчная и колоночная базы данных
MySQL
Самый именитый представитель нашего обзора программ для разработки базы данных. Бесплатная база данных MySQL существует с 1995 года и теперь принадлежит компании Oracle. СУБД имеет открытый исходный код. Также существует несколько платных версий, которые предлагают дополнительные функции, такие как гео-репликация кластера и автоматическое масштабирование.
Поскольку MySQL является отраслевым стандартом, она совместима практически со всеми операционными системами и написана на языках C и C ++. Это решение является отличным вариантом для международных пользователей. Сервер СУБД может выводить клиентам сообщения об ошибках на нескольких языках.
Достоинства
- Проверка на стороне сервера;
- Может использоваться как локальная база данных;
- Гибкая система привилегий и паролей;
- Безопасное шифрование всего трафика паролей;
- Библиотека, которая может быть встроена в автономные приложения;
- Предоставляет сервер в качестве отдельной программы для сетевого окружения клиент/сервер.
Недостатки практической разработки и администрирования баз данных MySQL Приобретена компанией Oracle:
- пользователи полагают, что MySQL больше не подпадает под категорию бесплатного и открытого программного обеспечения;
- больше не поддерживается сообществом;
- пользователи не могут исправлять ошибки и патчи;
- проигрывает другим решениям из-за медленных обновлений.
1 — Поднимаем базу данных PostgreSQL в Docker-контейнере
Это подготовительный этап. Мы будем работать с сервером PostgreSQL версии 11 и старше. Так как Docker все равно понадобится вам для последующей публикации приложения в Интернете, то убьем двух зайцев сразу и запустим сервер PostgreSQL в Docker-контейнере.
Устанавливаем Docker c официального сайта: .
Docker-контейнеры по умолчанию не хранят данные, поэтому необходимо создать volume, чтобы не потерять данные нашей базы после перезапуска или после остановки контейнера:
Теперь запустим нашу базу командой:
Мы запустили docker-контейнер с базой данных от имени root-пользователя. Давайте рассмотрим переданные параметры:
-
— задали пароль для пользователя базы данных, передав его через переменную окружения в контейнер
-
— задали имя пользователя базы данных аналогичным способом
-
— опубликовали 5432-ой порт контейнера во внешнюю среду. Подробнее о том, как устроена сеть Docker, можно прочитать тут
-
— примонтировали volume к нашему контейнеру. Теперь все данные, которые приложение в контейнере записало в , сохранятся на жестком диске. Иначе при остановке или перезапуске контейнера мы бы их потеряли.
-
— запустили команду в detached-режиме: можем закрыть консоль, а контейнер продолжит работать
-
— имя образа, на основе которого необходимо запустить контейнер. Подробнее про docker-образы можно прочитать
Проверим, что база работает. Для этого подключимся к ней через CLI:
Если все настроено верно, то указатель слева в терминале должен поменяться на postgres=#.
Создадим базу данных и дадим все права на нее нашему пользователю:
Подготовка закончена, переходим к написанию приложения.
Что нужно, для того чтобы создать базу данных в Microsoft SQL Server?
В данном разделе я представлю своего рода этапы создания базы данных в Microsoft SQL Server, т.е. это как раз то, что Вы должны знать и что у Вас должно быть, для того чтобы создать базу данных:
- У Вас должна быть установлена СУБД Microsoft SQL Server. Для обучения идеально подходит бесплатная редакция Microsoft SQL Server Express. Если Вы еще не установили SQL сервер, то вот подробная видео-инструкция, там я показываю, как установить Microsoft SQL Server 2017 в редакции Express;
- У Вас должна быть установлена среда SQL Server Management Studio (SSMS). SSMS – это основной инструмент, с помощью которого осуществляется разработка баз данных в Microsoft SQL Server. Эта среда бесплатная, если ее у Вас нет, то в вышеупомянутой видео-инструкции я также показываю и установку этой среды;
- Спроектировать базу данных. Перед тем как переходить к созданию базы данных, Вы должны ее спроектировать, т.е. определить все сущности, которые Вы будете хранить, определить характеристики, которыми они будут обладать, а также определить все правила и ограничения, применяемые к данным, в процессе их добавления, хранения и изменения. Иными словами, Вы должны определиться со структурой БД, какие таблицы она будет содержать, какие отношения будут между таблицами, какие столбцы будет содержать каждая из таблиц. В нашем случае, т.е. при обучении, этот этап будет скорей формальным, так как правильно спроектировать БД начинающий не сможет. Но начинающий должен знать, что переходить к созданию базы данных без предварительного проектирования нельзя, так как реализовать БД, не имея четкого представления, как эта БД должна выглядеть в конечном итоге, скорей всего не получится;
- Создать пустую базу данных. В среде SQL Server Management Studio создать базу данных можно двумя способами: первый — с помощью графического интерфейса, второй — с помощью языка T-SQL;
- Создать таблицы в базе данных. К этому этапу у Вас уже будет база данных, но она будет пустая, так как в ней еще нет никаких таблиц. На этом этапе Вам нужно будет создать таблицы и соответствующие ограничения;
- Наполнить БД данными. В базе данных уже есть таблицы, но они пусты, поэтому сейчас уже можно переходить к добавлению данных в таблицы;
- Создать другие объекты базы данных. У Вас уже есть и база данных, и таблицы, и данные, поэтому можно разрабатывать другие объекты БД, такие как: представления, функции, процедуры, триггеры, с помощью которых реализуется бизнес-правила и логика приложения.
Вот это общий план создания базы данных, который Вы должны знать, перед тем как начинать свое знакомство с Microsoft SQL Server и языком T-SQL.
В этой статье мы рассмотрим этап 4, это создание пустой базы данных, будут рассмотрены оба способа создания базы данных: и с помощью графического интерфейса, и с помощью языка T-SQL. Первые три этапа Вы должны уже сделать, т.е. у Вас уже есть установленный SQL Server и среда Management Studio, и примерная структура базы данных, которую Вы хотите реализовать, как я уже сказал, на этапе обучения этот пункт можно пропустить, а в следующих материалах я покажу, как создавать таблицы в Microsoft SQL Server пусть с простой, но с более-менее реальной структурой.
Общая система типов
Важной особенностью работы с базой данных является то, что в «1С:Предприятии 8» реализована общая система типов языка и полей баз данных. Иными словами, разработчик одинаковым образом определяет поля базы данных и переменные встроенного языка и одинаковым образом работает с ними.. Этим система «1С:Предприятие 8» выгодно отличается от универсальных инструментальных средств
Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Этим система «1С:Предприятие 8» выгодно отличается от универсальных инструментальных средств. Обычно, при создании бизнес-приложений с использованием универсальных сред разработки, используются отдельно поставляемые системы управления базами данных. А это значит, что разработчику приходится постоянно заботиться о преобразованиях между типами данных, поддерживаемыми той или иной системы управления базами данных, и типами, поддерживаемыми языком программирования.
Создание пользователя с использованием SSMS
-
В обозревателе объектов раскройте папку Базы данных .
-
Разверните базу данных, в которой создается новый пользователь базы данных.
-
Щелкните правой кнопкой мыши папку Безопасность, выберите пункт Создать, а затем Пользователь… .
-
В диалоговом окне Пользователь базы данных — создание на странице Общие выберите один из следующих типов пользователей в списке Тип пользователя:
-
пользователь SQL с именем для входа
-
пользователя SQL с паролем
-
Пользователь SQL без имени для входа
-
Пользователь, сопоставленный с сертификатом
-
Пользователь, сопоставленный с асимметричным ключом
-
пользователя Windows
-
-
Когда вы выбираете вариант, остальные параметры в диалоговом окне могут поменяться. Некоторые варианты применимы только к определенным типам пользователей базы данных. Некоторые параметры можно не заполнять. В результате будут использоваться значения по умолчанию.
User name
Введите имя нового пользователя. Если выбрать элемент Пользователь Windows в списке Тип пользователя, вы можете также щелкнуть многоточие (…) и открыть диалоговое окно Выбор пользователя или группы.Имя входа
Введите имя входа для пользователя. Также можно щелкнуть многоточие (…) , чтобы открыть диалоговое окно Выбор имени входа. Имя входа доступно, если выбрать элемент SQL-пользователь с именем входа или Пользователь Windows в списке Тип пользователя .Пароль и Подтверждение пароля
Введите пароль для пользователей, которым требуется доступ к базе данных.Язык по умолчанию
Укажите язык по умолчанию для пользователя.Схема по умолчанию
Укажите схему, которая будет владеть объектами, созданными пользователем. Также можно щелкнуть многоточие (…) , чтобы открыть диалоговое окно Выбор схемы. Схема по умолчанию доступна, если выбрать элемент SQL-пользователь с именем входа, SQL-пользователь без имени входа или Пользователь Windows в списке Тип пользователя .Имя сертификата
Укажите сертификат для пользователя базы данных. Также можно щелкнуть многоточие (…) , чтобы открыть диалоговое окно Выбор сертификата. Имя сертификата доступно, если выбрать элемент Пользователь, сопоставленный с сертификатом в списке Тип пользователя .Имя асимметричного ключа
Введите ключ для пользователя базы данных. Также можно щелкнуть многоточие (…) , чтобы открыть диалоговое окно Выбор асимметричного ключа. Имя асимметричного ключа доступно, если выбрать элемент Пользователь, сопоставленный с асимметричным ключом в списке Тип пользователя . -
Нажмите кнопку ОК.
Дополнительные параметры
Диалоговое окно Пользователь базы данных — создание также содержит параметры на четырех дополнительных страницах: Собственные схемы, Членство, Защищаемые объекты и Расширенные свойства.
-
На странице Собственные схемы перечислены все возможные схемы, которые принадлежат новому пользователю базы данных. Чтобы добавить схему для пользователя базы данных или удалить ее, на вкладке Схемы, принадлежащие этому пользователю установите или снимите флажки для соответствующей схемы.
-
На странице Членство приведен список всех ролей, к которым может принадлежать новый пользователь базы данных. Чтобы добавить роль для пользователя базы данных или удалить ее, на вкладке Членство ролей базы данных установите или снимите флажки для соответствующей роли.
-
На странице Защищаемые объекты перечислены все возможные защищаемые объекты и разрешения на эти объекты, которые могут быть предоставлены для имени входа.
-
Страница Расширенные свойства позволяет добавлять пользовательские свойства пользователям базы данных. На этой странице доступны следующие параметры.
База данных
Отображает имя выбранной базы данных. Это поле доступно только для чтения.Параметры сортировки
Отображает параметры сортировки, используемые для выбранной базы данных. Это поле доступно только для чтения.Свойства
Просмотрите или укажите расширенные свойства объекта. Каждое расширенное свойство состоит из пары имя/значение метаданных, связанных с объектом.Кнопка с многоточием (…)
Нажмите многоточие (…) рядом с полем Значение, чтобы открыть диалоговое окно Значение для расширенного свойства. Введите или просмотрите значение расширенного свойства в этом более просторном окне. Дополнительные сведения см. в разделе Диалоговое окно «Значение для расширенного свойства».Удаление
Удаляет выбранное расширенное свойство.
Достоинства реляционных баз
- Имеют простую структуру, которая подходит к большинству типов данных.
- Используют SQL, который широко распространен и по умолчанию поддерживает операции объединения.
- Позволяют быстро обновлять данные. Вся БД хранится на одном компьютере, а отношения между записями используются как указатели, то есть вы можете обновить одну запись — и все связанные с ней записи немедленно обновятся.
- Реляционные БД также поддерживают атомарные транзакции. Что это? Предположим, я хочу перевести X долларов от Алисы к Бобу. Я хочу осуществить 3 действия: уменьшить баланс Алисы на X, увеличить баланс Боба на X и задокументировать транзакцию. Я могу назначить эти действия атомарной единицей БД — или произойдут все действия, или ни одно. Это защищает от ошибок при сбоях.
PostgreSQL
PostgreSQL является еще одним выдающимся решением с открытым исходным кодом, работающим во всех основных операционных системах, включая Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64) и Windows. PostgreSQL полностью отвечает принципам ACID (атомарность, согласованность, изолированность, устойчивость).
Достоинства
- Возможность создания пользовательских типов данных и методов запросов;
- Среда разработки баз данных выполняет хранимые процедуры более чем на десятке языков программирования: Java, Perl, Python, Ruby, Tcl, C/C ++ и собственный PL/pgSQL;
- GiST (система обобщенного поиска): объединяет различные алгоритмы сортировки и поиска: B-дерево, B+-дерево, R-дерево, деревья частичных сумм и ранжированные B+ -деревья;
- Возможность создания для большего параллелизма без изменения кода Postgres, например, CitusDB.
Недостатки
- Система MVCC требует регулярной «чистки»: проблемы в средах с высокой скоростью транзакций;
- Разработка осуществляется обширным сообществом: слишком много усилий для улучшений.
Создание таблиц и ключей с помощью конструктор таблиц
В этом разделе вы создадите две таблицы, первичный ключ в каждой таблице и несколько строк образца данных. Вы также создадите внешний ключ, чтобы указать, как записи в одной таблице соответствуют записям в другой таблице.
Создание таблицы Customers
-
В Обозреватель сервера разверните узел подключения к данным , а затем узел сампледатабасе. mdf .
если не удается развернуть узел подключения к данным или отсутствует подключение сампледатабасе. mdf, нажмите кнопку Подключение к базе данных на панели инструментов обозреватель сервера. в диалоговом окне добавление соединения убедитесь, что в поле источник данных выбран Microsoft SQL Server файл базы данных , а затем найдите и выберите файл сампледатабасе. mdf. Завершите добавление подключения, нажав кнопку ОК.
-
Щелкните правой кнопкой мыши таблицы и выберите команду Добавить новую таблицу.
Будет открыт Конструктор таблиц, отобразится сетка с одной строкой по умолчанию, которая представляет один столбец в создаваемой таблице. Путем добавления строк в сетку будут добавлены столбцы в таблицу.
-
В сетке добавьте строку для каждой из следующих записей.
Имя столбца Тип данных Разрешить значения null False (не установлен) False (не установлен) True (установлен) True (установлен) -
Щелкните строку правой кнопкой мыши и выберите пункт Задать первичный ключ.
-
Щелкните строку по умолчанию () правой кнопкой мыши и выберите пункт Удалить.
-
Назовите таблицу «Клиенты» путем обновления первой строки в области скриптов, как показано в следующем примере:
Отобразятся примерно следующие сведения:
-
В левом верхнем углу Конструктор таблиц выберите Обновить.
-
В диалоговом окне Предварительный просмотр обновлений базы данных выберите обновить базу данных.
Таблица Customers создается в файле локальной базы данных.
Создание таблицы Orders
-
Создайте еще одну таблицу, а затем добавьте строку для каждой записи следующей таблицы.
Имя столбца Тип данных Разрешить значения null False (не установлен) False (не установлен) True (установлен) True (установлен) -
Задайте OrderID в качестве первичного ключа, а затем удалите строку по умолчанию.
-
Назовите таблицу «Заказы» путем обновления первой строки в области скриптов, как показано в следующем примере:
-
В левом верхнем углу Конструктор таблиц выберите Обновить.
-
В диалоговом окне Предварительный просмотр обновлений базы данных выберите обновить базу данных.
Таблица Orders создается в файле локальной базы данных. Если развернуть узел таблицы в обозреватель сервера, отобразятся две таблицы:
Создание внешнего ключа
-
В контекстной области в правой части сетки конструктор таблиц для таблицы Orders щелкните правой кнопкой мыши внешние ключи и выберите Добавить новый внешний ключ.
-
В появившемся текстовом поле замените текст ToTable на Customers.
-
в области T-SQL обновите последнюю строку, чтобы она соответствовала следующему примеру:
-
В левом верхнем углу Конструктор таблиц выберите Обновить.
-
В диалоговом окне Предварительный просмотр обновлений базы данных выберите обновить базу данных.
Создается внешний ключ.
10 — Резюме
Подведем итоги. В этой статье мы:
-
Научились поднимать базу данных PostgreSQL в Docker-контейнере
-
Поработали с файлами конфигурации приложения
-
Написали свой Accessor, который позволил нашему приложению получать данные из сторонних источников. По аналогии с ним можно создать каналы получения данных из других источников, например из стороннего API.
-
Создали модель Message, абстракцию над «сухой» строчкой в таблице базы данных
-
Узнали как асинхронно общаться с PostgreSQL из Python
-
Настроили alembic и с его помощью сгенерировали первую миграцию
-
Обратились из Python-кода к данным в нашей базе данных и отдали их в виде HTTP-ответа
Код для второй части статьи находится в этом репозитории.
Удаление базы данных в Microsoft SQL Server
В случае необходимости можно удалить базу данных. В реальности, конечно же, такое редко будет требоваться, но в процессе обучения, может быть, и часто. Это можно сделать также, как с помощью графического интерфейса, так и с помощью языка T-SQL.
В случае с графическим интерфейсом необходимо в обозревателе объектов щелкнуть правой кнопкой мыши по нужной базе данных и выбрать пункт «Удалить».
В окне «Удаление объекта» нажимаем «ОК». Для принудительного закрытия существующих подключений к БД можете поставить галочку «Закрыть существующие соединения».
В случае с T-SQL, для удаления базы данных достаточно написать следующую инструкцию (в БД также никто не должен работать).
DROP DATABASE TestDB;
Где DROP DATABASE — это инструкция для удаления базы данных, TestDB – имя базы данных. Иными словами, командой DROP объекты на SQL сервере удаляются.
Что такое схемы базы данных?
Когда дело доходит до выбора базы данных, одна из вещей, о которой вы должны подумать, — это форма ваших данных, модель, которой они будут следовать, и то, как сформированные отношения помогут нам при разработке схемы.
Схема базы данных — это план или архитектура того, как будут выглядеть наши данные. Он не содержит самих данных, а вместо этого описывает форму данных и то, как они могут быть связаны с другими таблицами или моделями. Запись в нашей базе данных будет экземпляром схемы базы данных. Он будет содержать все свойства, описанные в схеме.
Думайте о схеме базы данных как о типе структуры данных. Он представляет собой структуру и структуру содержимого данных организации.
Схема базы данных будет включать:
- Все важные или важные данные
- Единое форматирование для всех записей данных
- Уникальные ключи для всех записей и объектов базы данных
- Каждый столбец в таблице имеет имя и тип данных.
Размер и сложность схемы вашей базы данных зависит от размера вашего проекта. Визуальный стиль схемы базы данных позволяет программистам правильно структурировать базу данных и ее взаимосвязи, прежде чем переходить к коду. Процесс планирования дизайна базы данных называется моделированием данных.
Схемы важны для проектирования систем управления базами данных (СУБД) или систем управления реляционными базами данных (СУБД). СУБД — это программное обеспечение, которое хранит и извлекает пользовательские данные безопасным способом в соответствии с концепцией ACID.
Во многих компаниях ответственность за проектирование базы данных и СУБД обычно ложится на роль администратора базы данных (DBA). Администраторы баз данных несут ответственность за обеспечение беспрепятственного доступа к информации аналитикам данных и пользователям баз данных. Они работают вместе с командами менеджеров для планирования и безопасного управления базой данных организации.
MySQL Создание базы данных, используя MySQLi и PDO
Инструкция CREATE DATABASE используется для создания базы данных в MySQL.
В следующих примерах создается база данных с именем :
Пример MySQLi — объектно-ориентированный
<?php
// Подключение к MySQL
$servername = «localhost»; // локалхост
$username = «root»; // имя пользователя
$password = «»; // пароль если существует
// Создание соединения
$conn = new mysqli($servername, $username, $password);
// Проверка соединения
if ($conn->connect_error) {
die(«Ошибка подключения: » . $conn->connect_error);}
// Созданние базы данных
$sql = «CREATE DATABASE myDB»;
if ($conn->query($sql) === TRUE) {
echo «База данных создана успешно»;
} else {
echo «Ошибка создания базы данных: » . $conn->error;}
// Закрыть подключение
$conn->close();?>
Примечание: Когда создаете новую базу данных,
вы должны указать только три первых аргумента к объекту инфраструктуры (сервер, имя пользователя и пароль).
Внимание: Если вам нужно использовать определенный порт,
добавьте в пустую строку для базы данных имя аргумента:
Пример MySQLi — процессуальный
<?php
// Подключение к MySQL
$servername = «localhost»; // локалхост
$username = «root»; // имя пользователя
$password = «»; // пароль если существует
// Создание соединения
$conn = mysqli_connect($servername, $username, $password);
// Проверка соединения
if (!$conn) {
die(«Ошибка подключения: » . mysqli_connect_error());}
// Созданние базы данных
$sql = «CREATE DATABASE myDB»;
if (mysqli_query($conn, $sql)) {
echo «База данных создана успешно»;
} else {
echo «Ошибка создания базы данных: » . mysqli_error($conn);}
// Закрыть подключение
mysqli_close($conn);?>
Примечание: В следующем примере PDO создается база данных с именем :
Пример PDO
<?php
// Подключение к MySQL
$servername = «localhost»; // локалхост
$username = «root»; // имя пользователя
$password = «»; // пароль если существует
$dbname = «myDB»; // база данных
// Создание соединения и исключения
try {
$conn = new PDO(«mysql:host=$servername;dbname=myDBPDO», $username, $password);
// Установить режим ошибки PDO в исключение
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
// Созданние базы данных
$sql = «CREATE DATABASE myDBPDO»;
// Используйте exec (), поскольку результат не возвращается
$conn->exec($sql);
echo «База данных создана успешно<br>»;
}
catch(PDOException $e) // класс исключения {
echo $sql . «<br>» . $e->getMessage();
}
}
// Закрыть подключение
$conn = null;?>
Совет: Большим преимуществом PDO является то, что он имеет класс исключений для решения любых проблем,
которые могут возникнуть в наших запросах базы данных. Если исключение выдается внутри блока ,
сценарий прекращает выполнение и переходит непосредственно к первому блоку .
В блоке ниже оператор и сгенерировал сообщение об ошибке.
Достоинства документных баз
- Позволяют хранить объекты с разной структурой.
- Могут отображать почти все структуры данных, включая объекты на основе ООП, списки и словари, используя старый добрый JSON.
- Несмотря на то, что NoSQL не схематичны по своей природе, они часто поддерживают проверку схемы. Это значит, что вы можете сделать коллекцию со схемой. Эта схема не будет простой, как таблица: это будет JSON схема со специфическими полями.
- Запросы к NoSQL очень быстрые — каждая запись независима и, следовательно, время запроса не зависит от размера базы. По той же причине эта БД поддерживает параллельность.
- В NoSQL масштабирование БД осуществляется добавлением компьютеров и распределением данных между ними, этот метод называется горизонтальное масштабирование. Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
Типы движков баз данных MySQL
Каждый из примеров создания таблицы в этой статье до этого момента включал в себя определение ENGINE= . MySQL поставляется с несколькими различными движками баз данных, каждый из которых имеет свои преимущества. Используя директиву ENGINE =, можно выбрать, какой движок использовать для каждой таблицы. В настоящее время доступны следующие движки баз данных MySQL:
- InnoDB — был представлен вMySQL версии 4.0 и классифицирован как безопасная среда для транзакций.Ее механизм гарантирует, что все транзакции будут завершены на 100%. При этом частично завершенные транзакции (например, в результате отказа сервера или сбоя питания) не будут записаны. Недостатком InnoDB является отсутствие поддержки полнотекстового поиска.
- MyISAM — высокопроизводительный движок с поддержкой полнотекстового поиска. Эта производительность и функциональность обеспечивается за счет отсутствия безопасности транзакций.
- MEMORY— с точки зрения функционала эквивалентен MyISAM, за исключением того, что все данные хранятся в оперативной памяти, а не на жестком диске. Это обеспечивает высокую скорость обработки. Временный характер данных, сохраняемых в оперативной памяти, делает движок MEMORY более подходящим для временного хранения таблиц.
Движки различных типов могут сочетаться в одной базе данных. Например, некоторые таблицы могут использовать движок InnoDB, а другие — MyISAM. Если во время создания таблицы движок не указывается, то по умолчанию MySQL будет использовать MyISAM.
Чтобы указать тип движка, который будет использоваться для таблицы, о поместите соответствующее определение ENGINE= после определения столбцов таблицы:
CREATE TABLE tmp_orders
{
tmp_number int NOT_NULL,
tmp_quantity int NOT_NULL,
tmp_desc char(20) NOT_NULL,
PRIMARY KEY (tmp_number)
) ENGINE=MEMORY;
Пожалуйста, опубликуйте ваши комментарии по текущей теме статьи. За комментарии, отклики, лайки, дизлайки, подписки низкий вам поклон!
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached
Объектный / табличный доступ к данным
Штатной возможностью «1С:Предприятия 8» является поддержка двух способов доступа к данным — объектного (для чтения и записи) и табличного (для чтения).
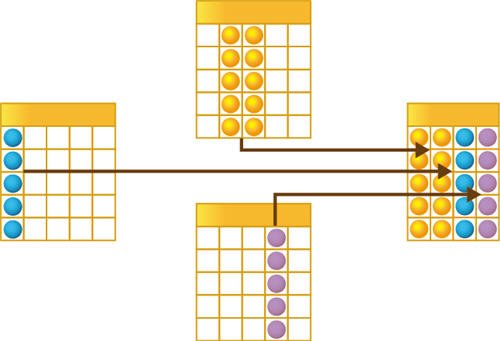
В объектной модели разработчик оперирует объектами встроенного языка. В этой модели обращения к объекту, например документу, происходят как к единому целому — он полностью загружается в память, вместе с вложенными таблицами, к которым можно обращаться средствами встроенного языка как к коллекциям записей и т.д.
При манипулировании данными в объектной модели обеспечивается сохранение целостности объектов, кэширование объектов, вызов соответствующих обработчиков событий и т.д.
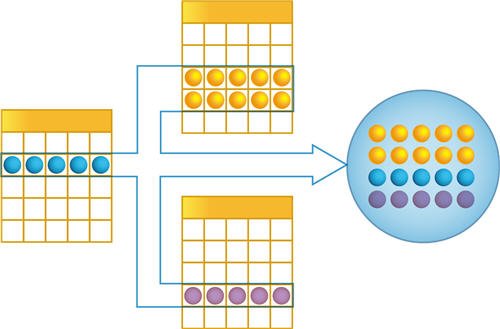
В табличной модели все множество объектов того или иного класса представляется как совокупность связанных между собой таблиц, к которым можно обращаться при помощи запросов — как к отдельной таблице, так и к нескольким таблицам во взаимосвязи:
В этом случае разработчик получает доступ к данным сразу нескольких объектов, что очень удобно для анализа больших объемов данных, например, при создании отчетов. Однако в силу того, что данные, выбираемые таким способом, содержат не все, а лишь некоторые реквизиты анализируемых объектов, табличный способ доступа не позволяет изменять эти данные.
8 — Alembic: добавляем взаимодействие с базой данных
В последнем шаге на сегодня рассмотрим взаимодействие с базой данных: получение и создание записей. Для этого необходимо создать новый View в файле app/forum/views.py. Добавьте этот код в конец файла:
В этом View мы получаем отсортированные по id сообщения в порядке убывания. Так как номера id добавляются в базу последовательно, то сначала будут отданы сообщения, добавленные последними. Затем преобразуем Python-модели в список словарей, преобразуем их в json-формат, а затем возвращаем их в ответ на запрос.
Не забудьте указать путь, по которому будет доступен данный View. В файле app/forum/routes.py в функции добавьте:
Для проверки вручную добавьте вручную пару сообщений. Для этого откройте psql:
Теперь выполните команды:
С помощью команды мы подключаемся к конкретной базе данных и можем выполнять запросы к ее таблицам, например, выполнить команду .
Чтобы посмотреть имеющиеся таблицы в базе данных, после подключения к ней необходимо выполнить команду :
Заметьте, что у нас существуют две таблицы и одна последовательность:
— в ней хранится номер последней примененной к базе миграции, которая должна соответствовать префиксу в последнем примененном файлом миграции:
— таблица, где содержатся данные о сообщениях:
— последовательность, которая используется для генерации новых id сообщений в базе.

Готово! Мы получили данные, которые хранятся в нашей базе и передали их в ответ на запрос.
Чтобы добавить данные не вручную, создайте еще один View. Откройте файл app/forum/views.py и добавьте в конец следующий код:
Можно заметить, что в этом коде мы создаем новое сообщение в базе данных — то есть записываем новую строчку в базу, а затем возвращаем созданное сообщение обратно.
Отдельно остановимся на том, как мы получаем данные извне: строчка позволяет получить json-информацию, которая пришла вместе с запросом. Почему нам приходится использовать для получения данных из объекта запроса? Дело в том, что aiohttp стремится оптимизировать взаимодействие с сетью и не получать данных больше того, что необходимо в данный момент. Пример: мы можем получить первый HTTP-пакет запроса и увидеть, что метод запроса неверен. Тогда мы не будем выполнять дальнейшие операции, или читать небольшими порциями, а не считывать все данные запроса целиком.
Изначально объект — это информация из первого считанного HTTP-пакета (их может быть несколько, если данных много), поэтому в нем сразу же доступны метод запроса, заголовки и адрес отправителя. Для получения тела запроса необходимо выполнить асинхронную операцию, после выполнения которой в будет находиться обычный Python-словарь.
Добавим путь к нашему новому View в app/forum/routes.py в функции :