Screaming frog seo spider 15.2 + key
Содержание:
- Troubleshooting
- Linux
- Small Update – Version 2.22 Released 3rd December 2013
- Exporting Data
- 4) Security Checks
- 5) Internal Link Score
- Small Update – Version 15.1 Released 14th April 2021
- Small Update – Version 15.2 Released 18th May 2021
- 5) Агрегированная структура сайта
- 1) Scheduling
- Other Updates
- 7) Web Forms Authentication (Crawl Behind A Login)
- Screaming Frog SEO Spider 12.5
- 3) Indexability & Indexability Status
- Screaming Frog SEO Spider: программный экспресс-аудит сайта
- 1) Structured Data & Validation
- 1) ‘Fetch & Render’ (Rendered Screen Shots)
- Small Update – Version 13.2 Released 4th August 2020
- Small Update – Version 13.1 Released 15th July 2020
- 1) Google Search Analytics Integration
Troubleshooting
If set up correctly, this process should be seamless but occasionally Google might catch wind of what you’re up too and come down to stop your fun with an annoying anti-bot captcha test.
If this happens just pause your crawl, load up a PSI page in a browser to solve the captcha, then jump back in the tool highlight the URLs that did not extract any data right click > Re-Spider.

If this continues the likelihood is you have your crawl speed set too high, if you lower it down a bit in the options mentioned above it should put you back on track.
I’ve also noticed a number of comments reporting the PSI page not properly rendering and nothing being extracted. If this happens it might be worth a clear to the default config (File > Configuration > Clear to default). Next, make sure the user-agent is set to ScreamingFrog. Finally, ensure you have the following configuration options ticked (Configuration > Spider):
- Check Images
- Check CSS
- Check JavaScript
- Check SWF
- Check External Links
If for any reason, the page is rendering correctly but some scores weren’t extracted, double check the Xpaths have been entered correctly and the dropdown is changed to ‘Extract Text’. Secondly, it’s worth checking PSI actually has that data by loading it in a browser — much of the real-world data is only available on high-volume pages.
Linux
This screamingfrogseospider binary is placed in your path during installation. To run this open a terminal and follow the examples below.
To start normally:
screamingfrogseospider
To open a saved crawl file:
screamingfrogseospider /tmp/crawl.seospider
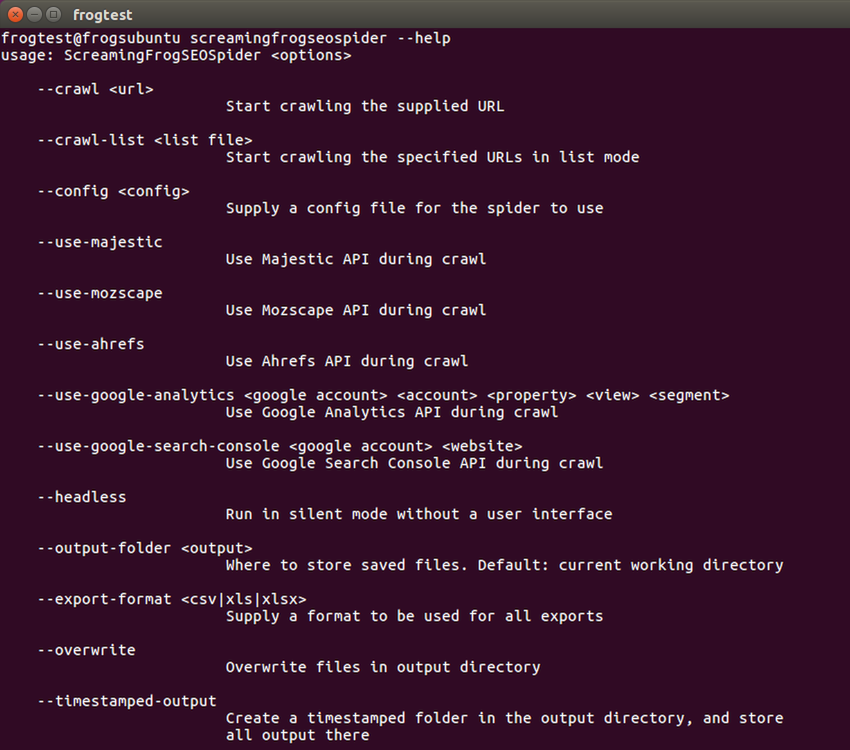
To see a full list of the command line options available:
screamingfrogseospider --help
To start the UI and immediately start crawling:
screamingfrogseospider --crawl https://www.example.com/
To start headless, immediately start crawling and save the crawl along with Internal->All and Response Codes->Client Error (4xx) filters:
screamingfrogseospider --crawl https://www.example.com --headless --save-crawl --output-folder /tmp/cli --export-tabs "Internal:All,Response Codes:Client Error (4xx)"
To load a saved crawl file and export the ‘Internal’ tab to the desktop.:
screamingfrogseospider --headless --load-crawl ~/Desktop/crawl.seospider --output-folder ~/Desktop/ --export-tabs "Internal:All"
In order to utilize JavaScript Rendering when running headless in Linux a display is required. You can use a Virtual Frame Buffer to simulate having a display attached. See full details here.
Please see the full list of command line options below.
Small Update – Version 2.22 Released 3rd December 2013
We have just released another small update to version 2.22 of the Screaming Frog SEO spider. There’s a couple of tweaks, which include –
- We are now identified Apple developers! So hopefully Mac users will no longer receive a warning that we are ‘unidentified’ or the ‘file is damaged’ upon install.
- From feedback of individual cell and row selection in 2.21, we have improved this and introduced row numbers.
That’s it for now, if you spot any issues, please as always do let us know via our support. Thanks again for all the kind comments below, we are busy working on lots of new features for our next release!
Exporting Data
You’re able to export all data into spread sheets from the crawl. Simply click the ‘export’ button in the top left hand corner to export data from the top window tabs and filters.
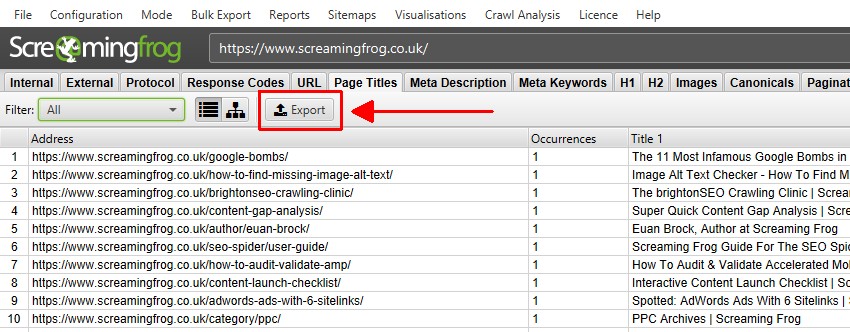
To export lower window data, right click on the URL(s) that you wish to export data from in the top window, then click on one of the options.
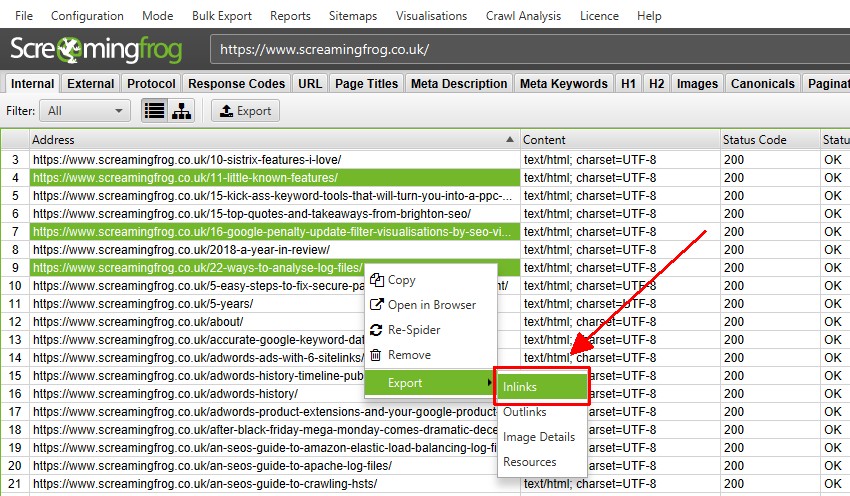
There’s also a ‘Bulk Export’ option located under the top level menu. This allows you to export the source links, for example the ‘inlinks’ to URLs with specific status codes such as 2XX, 3XX, 4XX or 5XX responses.
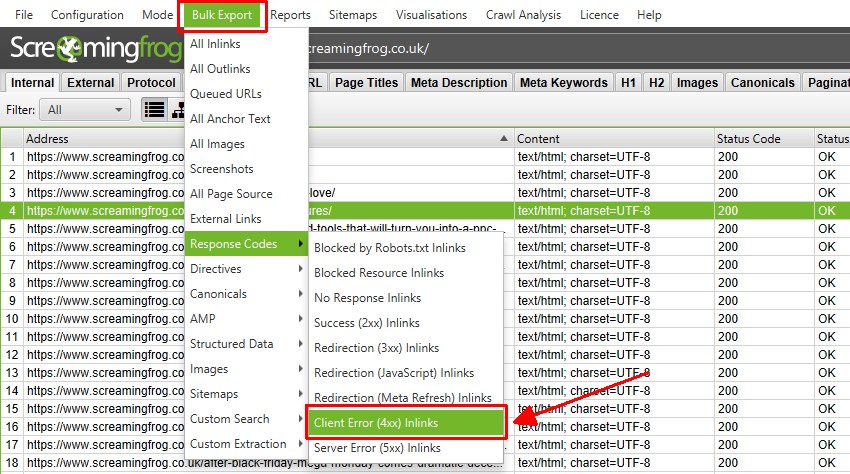
In the above, selecting the ‘Client Error 4XX In Links’ option above will export all inlinks to all error pages (pages that link to 404 error pages).
4) Security Checks
The ‘Protocol’ tab has been renamed to ‘‘ and more up to date security-related checks and filters have been introduced.
While the SEO Spider was already able to identify HTTP URLs, mixed content and other insecure elements, exposing them within filters helps you spot them more easily.
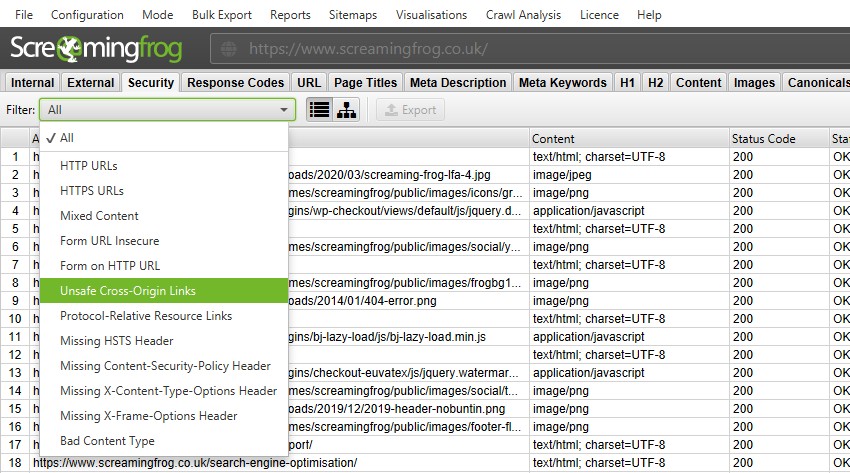
You’re able to quickly find mixed content, issues with insecure forms, unsafe cross-origin links, protocol-relative resource links, missing security headers and more.
The old insecure content report remains as well, as this checks all elements (canonicals, hreflang etc) for insecure elements and is helpful for HTTPS migrations.
The new security checks introduced are focused on the most common issues related to SEO, web performance and security, but this functionality might be extended to cover additional security checks based upon user feedback.
5) Internal Link Score
A useful way to evaluate and improve internal linking is to calculate internal PageRank of URLs, to help get a clearer understanding about which pages might be seen as more authoritative by the search engines.
The SEO Spider already reports on a number of useful metrics to analyse internal linking, such as crawl depth, the number of inlinks and outlinks, the number of unique inlinks and outlinks, and the percentage of overall URLs that link to a particular URL. To aid this further, we have now introduced an advanced ‘link score’ metric, which calculates the relative value of a page based upon its internal links.
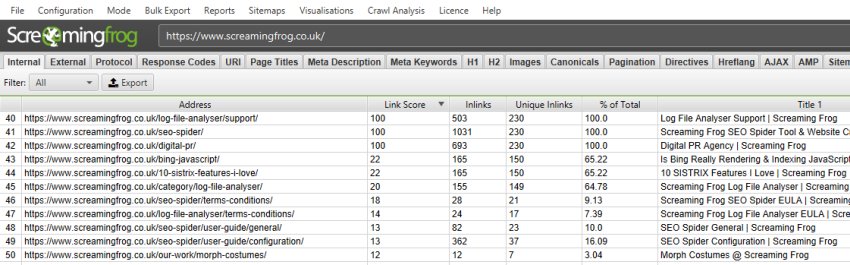
This uses a relative 0-100 point scale from least to most value for simplicity, which allows you to determine where internal linking might be improved.
The link score metric algorithm takes into consideration redirects, canonicals, nofollow and much more, which we will go into more detail in another post.
This is a relative mathematical calculation, which can only be performed at the end of a crawl when all URLs are known. Previously, every calculation within the SEO Spider has been performed at run-time during a crawl, which leads us on to the next feature.
Small Update – Version 15.1 Released 14th April 2021
We have just released a small update to version 15.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Fix bug that allowed selection of a project directory in ‘Compare’ mode triggering a crash.
- Fix bug in crawls dialog with crawls not being ordered by modified date.
- Fix tool tip alignment issues in Compare mode.
- Fix bug in JavaScript rendering causing a stall when crawling PDFs.
- Fix bug where re-spidered URLs that previously failed rendering appeared in the External tab.
- Fix crash in Locales that use non ASCII numbering systems when crawling sites with multiple instances of HTML elements.
- Fix crash removing URLs from Tree View.
Small Update – Version 15.2 Released 18th May 2021
We have just released a small update to version 15.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- Include ‘Current Indexability Status’ (and previous) columns in ‘Change Detection > Indexability’.
- Added right-click ‘Respider’ to details panel.
- Add status and status code to right click ‘Export > Inlinks’.
- Improve usability of comparison mode crawls dialog.
- Improve usability of Crawl Comparison URL Mapping UI.
- Remove new lines from Link Paths.
- Fix various issues with Forms based authentication.
- Fix bug where cells containing lots of data would cause Google Sheets exports to fail.
- Fix bug reading sitemaps containing a DOCTYPE.
- Fix bug where not all image types were shown in the Image Preview tab.
- Fix crash performing a search in the master view after changing a Custom Search or Extraction.
- Fix bug where doing a respider on loaded in completed crawl with GSC/GA looses columns in master view when saved.
- Fix bug with change detection metrics missing when upgrading crawl to 15.2.
- Fix bug with Server Response Times columns showing incorrect data if ‘server response times category’ is also configured.
- Fix bug with persistent spell check dictionary being cleared on startup.
- Fix bug with Word Cloud Visualisation HTML export not working.
- Fix bug with trailing slashes being stripped from file names in screenshots bulk export.
- Fix bug with class name shown in Gnome menu on Ubuntu 18.04.
- Fix bug with SERP description clipping behind table.
- Fix crash in Image Details preview pane.
- Fix bug with PSI exports showing headings as Secs, but data as MS.
- Fix Duplicate ‘Max Image Size’ label in Spider Preferences.
- Fix crash with using an invalid regex in Regex Replace UI.
5) Агрегированная структура сайта
SEO Spider теперь отображает количество URL-адресов, обнаруженных в каждом каталоге, в дереве каталогов (к которому вы можете получить доступ через значок дерева рядом с «Экспорт» на верхних вкладках).
Это помогает лучше понять размер и архитектуру веб-сайта, и некоторые пользователи считают его более логичным в использовании, чем традиционное представление списка.
Наряду с этим обновлением команда разработчиков улучшила правую вкладку «Структура сайта», чтобы отобразить агрегированное представление веб-сайта в виде дерева каталогов. Это помогает быстро визуализировать структуру веб-сайта и с первого взгляда определять, где возникают проблемы, например, индексируемость различных путей.
Если вы нашли области сайта с неиндексируемыми URL-адресами, вы можете переключить «вид», чтобы проанализировать «статус индексируемости» этих различных сегментов пути, чтобы увидеть причины, по которым они считаются неиндексируемыми.
Вы также можете переключить представление на глубину сканирования по каталогам, чтобы помочь выявить любые проблемы с внутренними ссылками на разделы сайта и многое другое.
Этот более широкий агрегированный вид веб-сайта должен помочь вам визуализировать архитектуру и принимать более обоснованные решения для различных разделов и сегментов.
1) Scheduling
You can now to run automatically within the SEO Spider, as a one off, or at chosen intervals.
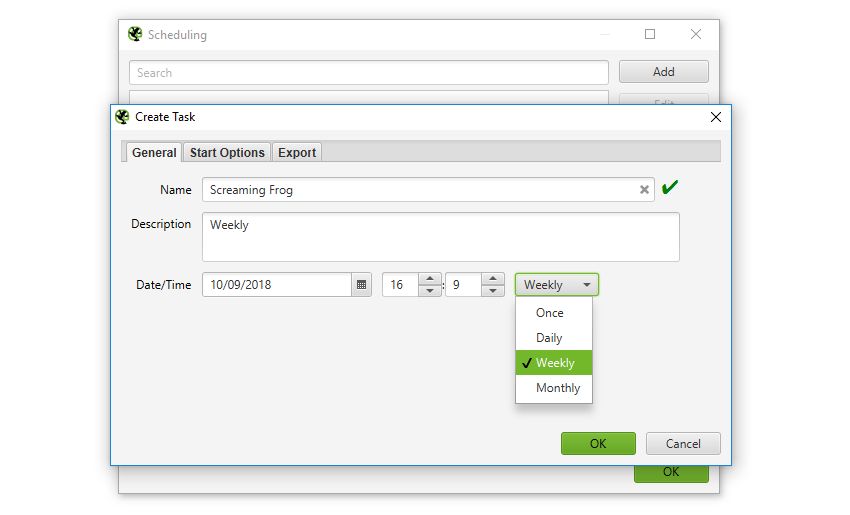
You’re able to pre-select the (spider, or list), saved , as well as APIs (, , , , ) to pull in any data for the scheduled crawl.
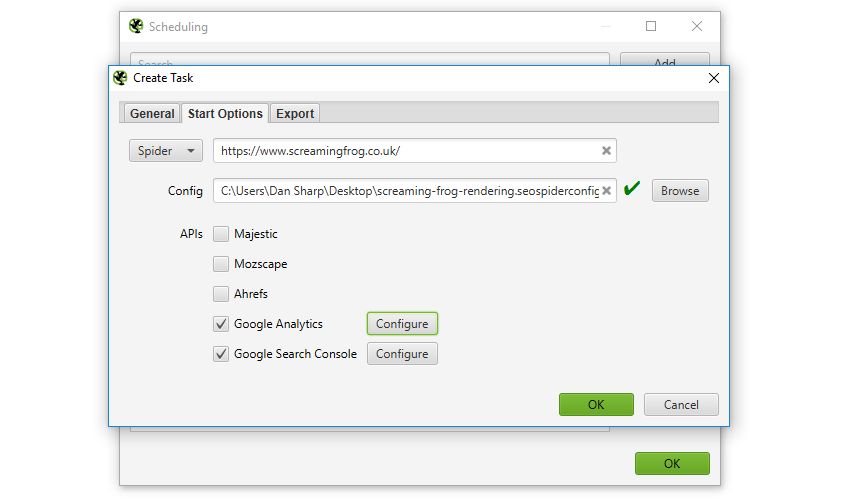
You can also automatically file and export any of the tabs, filters, , or XML Sitemaps to a chosen location.
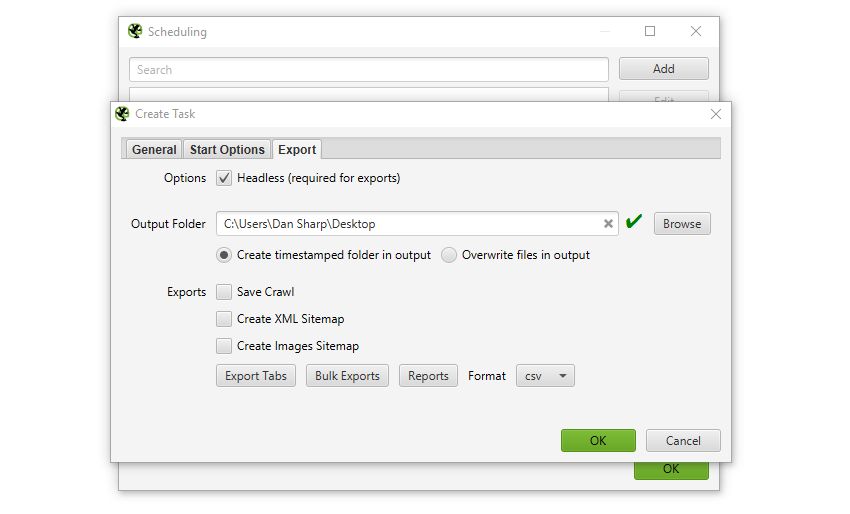
This should be super useful for anyone that runs regular crawls, has clients that only allow crawling at certain less-than-convenient ‘but, I’ll be in bed!’ off-peak times, uses crawl data for their own automatic reporting, or have a developer that needs a broken links report sent to them every Tuesday by 7 am.
The keen-eyed among you may have noticed that the SEO Spider will run in headless mode (meaning without an interface) when scheduled to export data – which leads us to our next point.
Other Updates
Version 13.0 also includes a number of smaller updates and bug fixes, outlined below.
- The has been updated with the new Core Web Vitals metrics (Largest Contentful Paint, First Input Delay and Cumulative Layout Shift). ‘Total Blocking Time’ Lighthouse metric and ‘Remove Unused JavaScript’ opportunity are also now available. Additionally, we’ve introduced a new ‘JavaScript Coverage Summary’ report under ‘Reports > PageSpeed’, which highlights how much of each JavaScript file is unused across a crawl and the potential savings.
- Following the Log File Analyser version 4.0, the SEO Spider has been updated to Java 11. This means it can only be used on 64-bit machines.
- iFrames can now be stored and crawled (under ‘Config > Spider > Crawl’).
- Fragments are no longer crawled by default in JavaScript rendering mode. There’s a new ‘Crawl Fragment Identifiers’ configuration under ‘Config > Spider > Advanced’ that allows you to crawl URLs with fragments in any rendering mode.
- A tonne of Google features for structured data validation have been updated. We’ve added support for COVID-19 Announcements and Image Licence features. Occupation has been renamed to Estimated Salary and two deprecated features, Place Action and Social Profile, have been removed.
- All Hreflang ‘confirmation links’ named filters have been updated to ‘return links’, as this seems to be the common naming used by Google (and who are we to argue?). Check out our How To Audit Hreflang guide for more detail.
- Two ‘AMP’ filters have been updated, ‘Non-Confirming Canonical’ has been renamed to ‘Missing Non-AMP Return Link’, and ‘Missing Non-AMP Canonical’ has been renamed to ‘Missing Canonical to Non-AMP’ to make them as clear as possible. Check out our How To Audit & validate AMP guide for more detail.
- The ‘Memory’ configuration has been renamed to ‘Memory Allocation’, while ‘Storage’ has been renamed to ‘Storage Mode’ to avoid them getting mixed up. These are both available under ‘Config > System’.
- Custom Search results now get appended to the Internal tab when used.
- The Forms Based Authentication browser now shows you the URL you’re viewing to make it easier to spot sneaky redirects.
- Deprecated APIs have been removed for the .
That’s everything. If you experience any problems, then please do just let us know via our support and we’ll help as quickly as possible.
Thank you to everyone for all their feature requests, feedback, and bug reports. Apologies for anyone disappointed we didn’t get to the feature they wanted this time. We prioritise based upon user feedback (and a little internal steer) and we hope to get to them all eventually.
Now, go and download version 13.0 of the Screaming Frog SEO Spider and let us know what you think!
7) Web Forms Authentication (Crawl Behind A Login)
The SEO Spider has standards-based authentication for some time, which enables users to crawl staging and development sites. However, there are other web forms and areas which require you to log in with cookies which have been inaccessible, until now.
We have introduced a new ‘authentication’ configuration (under ‘Configuration > Authentication), which allows users to log in to any web form within the SEO Spider Chromium browser, and then crawl it.
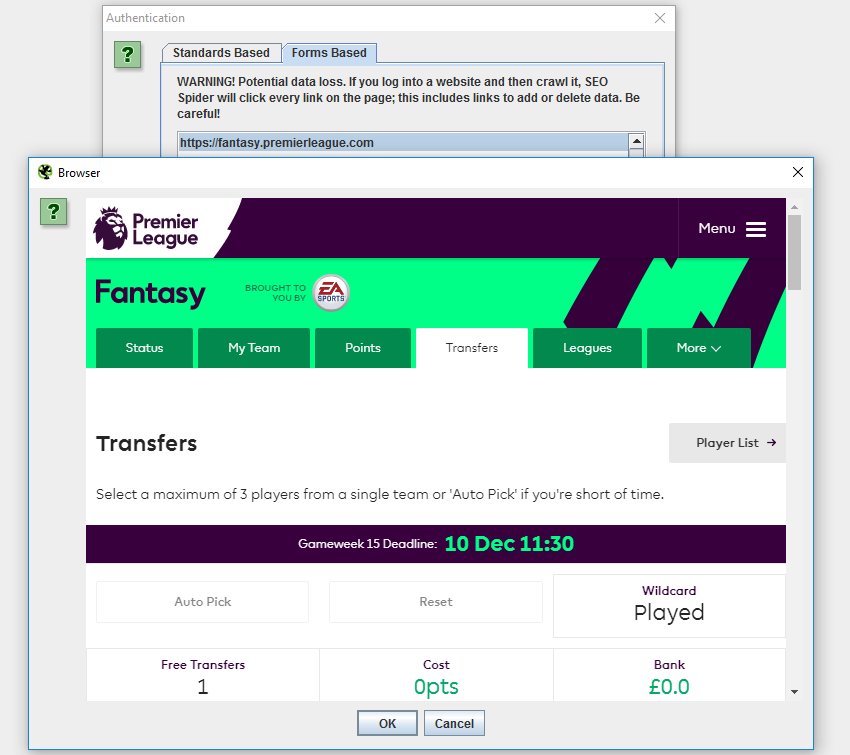
This means virtually all password-protected areas, intranets and anything which requires a web form login can now be crawled.
Please note – This feature is extremely powerful and often areas behind logins will contain links to actions which a user doesn’t want to press (for example ‘delete’). The SEO Spider will obviously crawl every link, so please use responsibly, and not on your precious fantasy football team. With great power comes great responsibility(!).
You can block the SEO Spider from crawling links or areas by using the or .
Screaming Frog SEO Spider 12.5
Screaming Frog SEO Spider is a software application that was developed with Java, in order to provide users with a simple means of gathering SEO information about any given site, as well as generate multiple reports and export the information to the HDD.
Clear-cut GUI The interface you come across might seem a bit cluttered, as it consists of a menu bar and multiple tabbed panes which display various information. However, a comprehensive User Guide and some FAQs are available on the developer’s website, which is going to make sure that both power and novice users can easily find their way around it, without encountering any kind of issues.
View internal and external links, filter and export them It is possible to analyze a specified URL, and view a list of internal and external links in separate tabs. The first come along with details such as address, type of content, status code, title, meta description, keywords, size, word count, level, hash and external out links, while the latter only reveals info such as address, content, status, level and inlinks. Both can be filtered according to HTML, javascript, CSS, images, PDF, Flash or other coordinates, while it is possible to export them to a CSV, XLS or XLSX format.
View further details and graphs, and generate reports In addition to that, you can check the response time of multiple links, view page titles, their occurrences, length and pixel width. It is possible to view huge lists with meta keywords and their length, headers and images. Graphical representations of certain situations are also available in the main window, along with a folder structure of all SEO elements analyzed, as well as stats pertaining to the depth of the website and average response time.
It is possible to use a proxy server, create a site map and save it to the HDD using an XML extension and generate multiple reports pertaining to crawl overview, redirect chains and canonical errors.
Bottom line To conclude, Screaming Frog SEO Spider is an efficient piece of software for those which are interested in analyzing their website from a SEO standpoint. The interface requires some getting used to it, the response time is good and we did not come by any errors or bugs. CPU and memory usage is not particularly high, which means that the computer’s performance is not going to be affected most of the times.
Compatibility: OS X 10.9 or later 64-bitHomepage https://www.screamingfrog.co.uk
3) Indexability & Indexability Status
This is not the third biggest feature in this release, but it’s important to understand the concept of we have introduced into the SEO Spider, as it’s integrated into many old and new features and data.
Every URL is now classified as either ‘Indexable‘ or ‘Non-Indexable‘.
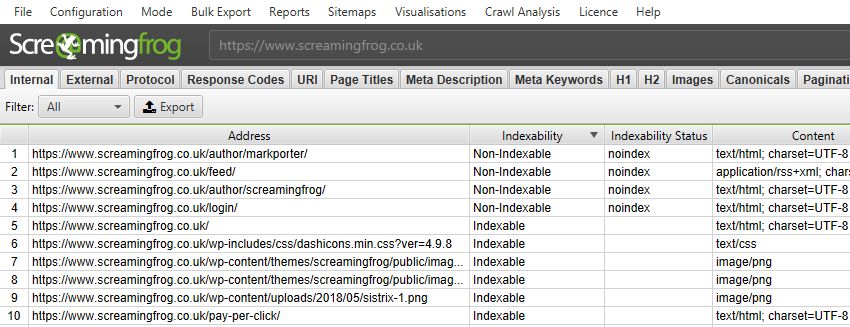
These two phrases are now commonplace within SEO, but they don’t have an exact definition. For the SEO Spider, an ‘Indexable’ URL means a page that can be crawled, responds with a ‘200’ status code and is permitted to be indexed.
This might differ a little from the search engines, which will index URLs which can’t be crawled and content that can’t be seen (such as those blocked by robots.txt) if they have links pointing to them. The reason for this is for simplicity, it helps to bucket and organise URLs into two distinct groups of interest.
Each URL will also have an indexability status associated with it for quick reference. This provides a reason why a URL is ‘non-indexable’, for example, if it’s a ‘Client Error’, ‘Blocked by Robots.txt, ‘noindex’, ‘Canonicalised’ or something else (and perhaps a combination of those).
This was introduced to make auditing more efficient. It makes it easier when you export data from the internal tab, to quickly identify which URLs are canonicalised for example, rather than having to run a formula in a spreadsheet. It makes it easier at a glance to review whether a URL is indexable when reviewing page titles, rather than scanning columns for canonicals, directives etc. It also allows the SEO Spider to use a single filter, or two columns to communicate a potential issue, rather than six or seven.
Screaming Frog SEO Spider: программный экспресс-аудит сайта
Screaming Frog SEO Spider позволяет быстро выявить такие проблемы как:
- внешние и внутренние битые ссылки,
- отсутствующие, слишком короткие или чрезмерно длинные TITLE,
- отсутствующий тег Meta Description,
- страницы с наибольшим весом,
- неоптимизированные изображения большого размера,
- страницы-дубли,
- отсутствие H1,
- страницы со слишком большим уровнем вложенности.
Также Screaming Frog SEO Spider позволяет выявить наиболее сильные страницы сайта, имеющие максимальное количество внутренних ссылок. Это позволит подкорректировать структуру web-ресурса таким образом, чтобы самые важные для продвижения разделы имели бы максимальное число ссылающихся страниц.
1) Structured Data & Validation
Structured data is becoming increasingly important to provide search engines with explicit clues about the meaning of pages, and enabling special search result features and enhancements in Google.
The SEO Spider now allows you to crawl and extract structured data from the three supported formats (JSON-LD, Microdata and RDFa) and validate it against Schema.org specifications and Google’s 25+ search features at scale.
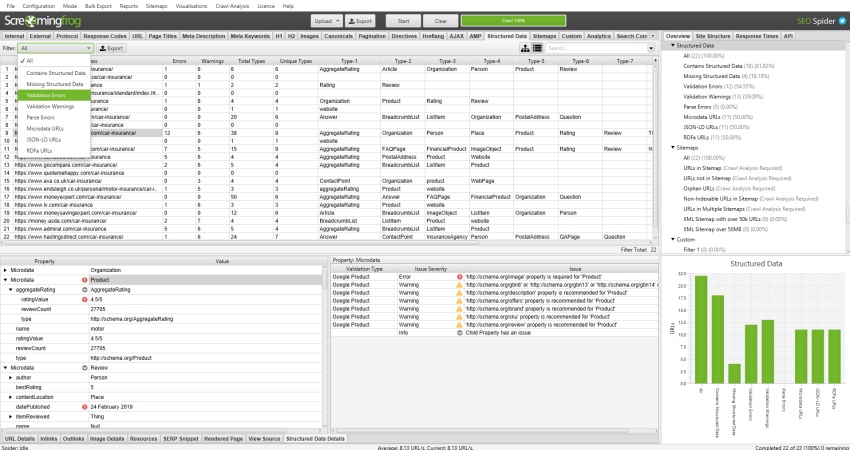
To extract and validate structured data you just need to select the options under ‘Config > Spider > Advanced’.
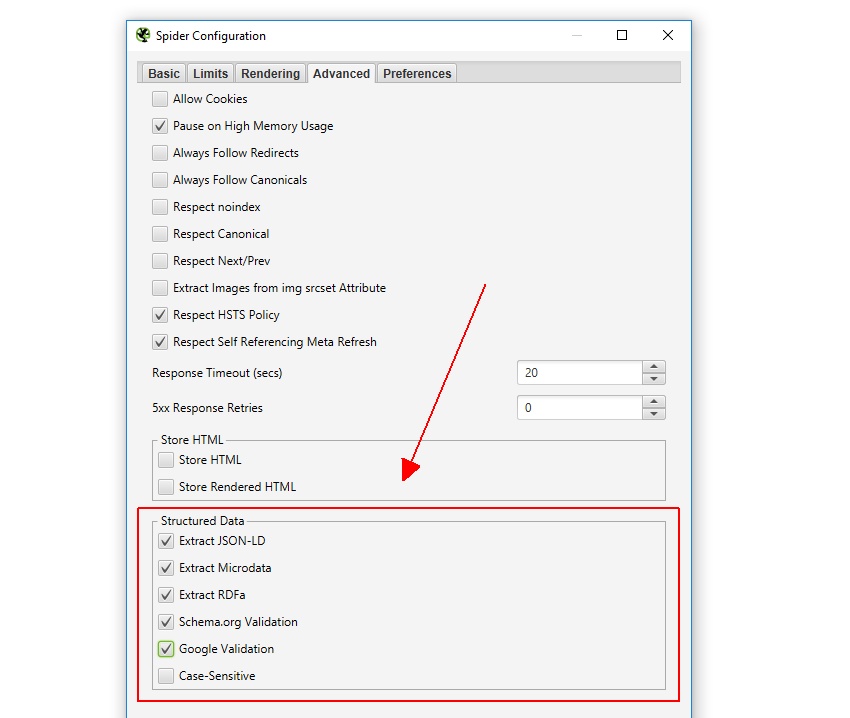
Structured data itemtypes will then be pulled into the ‘Structured Data’ tab with columns for totals, errors and warnings discovered. You can filter URLs to those containing structured data, missing structured data, the specific format, and by validation errors or warnings.
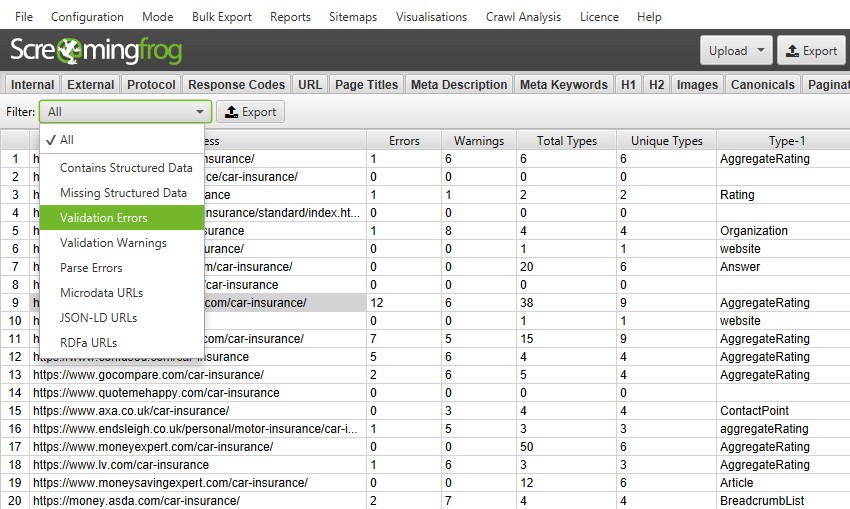
The structured data details lower window pane provides specifics on the items encountered. The left-hand side of the lower window pane shows property values and icons against them when there are errors or warnings, and the right-hand window provides information on the specific issues discovered.
The right-hand side of the lower window pane will detail the validation type (Schema.org, or a Google Feature), the severity (an error, warning or just info) and a message for the specific issue to fix. It will also provide a link to the specific Schema.org property.
In the random example below from a quick analysis of the ‘car insurance’ SERPs, we can see lv.com have Google Product feature validation errors and warnings. The right-hand window pane lists those required (with an error), and recommended (with a warning).
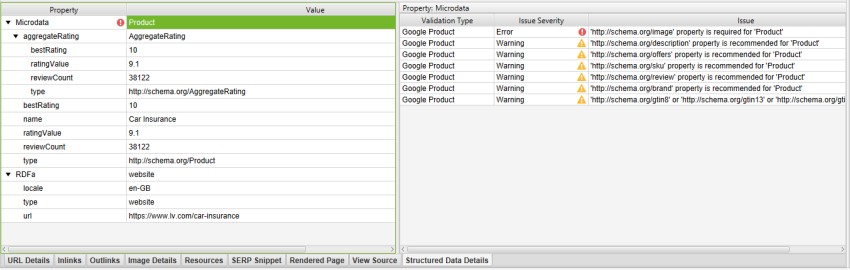
As ‘product’ is used on these pages, it will be validated against Google product feature guidelines, where an image is required, and there are half a dozen other recommended properties that are missing.
Another example from the same SERP, is Hastings Direct who have a Google Local Business feature validation error against the use of ‘UK’ in the ‘addressCountry‘ schema property.
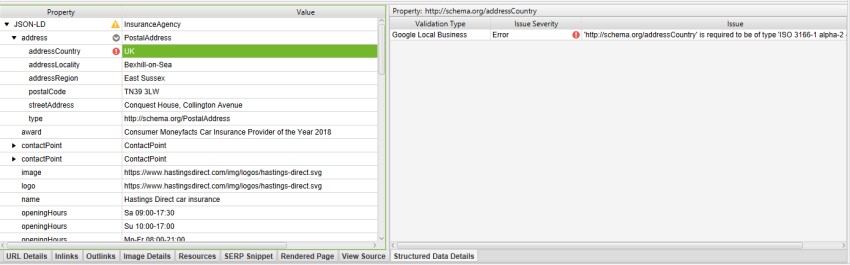
The right-hand window pane explains that this is because the format needs to be two-letter ISO 3166-1 alpha-2 country codes (and the United Kingdom is ‘GB’). If you check the page in Google’s structured data testing tool, this error isn’t picked up. Screaming Frog FTW.
The SEO Spider will validate against 26 of Google’s 28 search features currently and you can see the full list in our section of the user guide.
As many of you will be aware, frustratingly Google don’t currently provide an API for their own Structured Data Testing Tool (at least a public one we can legitimately use) and they are slowly rolling out new structured data reporting in Search Console. As useful as the existing SDTT is, our testing found inconsistency in what it validates, and the results sometimes just don’t match Google’s own documented guidelines for search features (it often mixes up required or recommended properties for example).
We researched alternatives, like using the Yandex structured data validator (which does have an API), but again, found plenty of inconsistencies and fundamental differences to Google’s feature requirements – which we wanted to focus upon, due to our core user base.
Hence, we went ahead and built our own structured data validator, which considers both Schema.org specifications and Google feature requirements. This is another first to be seen in the SEO Spider, after previously introducing innovative new features such as JavaScript Rendering to the market.
There are plenty of nuances in structured data and this feature will not be perfect initially, so please do let us know if you spot any issues and we’ll fix them up quickly. We obviously recommend using this new feature in combination with Google’s Structured Data Testing Tool as well.
1) ‘Fetch & Render’ (Rendered Screen Shots)
You can now view the rendered page the SEO Spider crawled in the new ‘Rendered Page’ tab which dynamically appears at the bottom of the user interface when crawling in mode. This populates the lower window pane when selecting URLs in the top window.
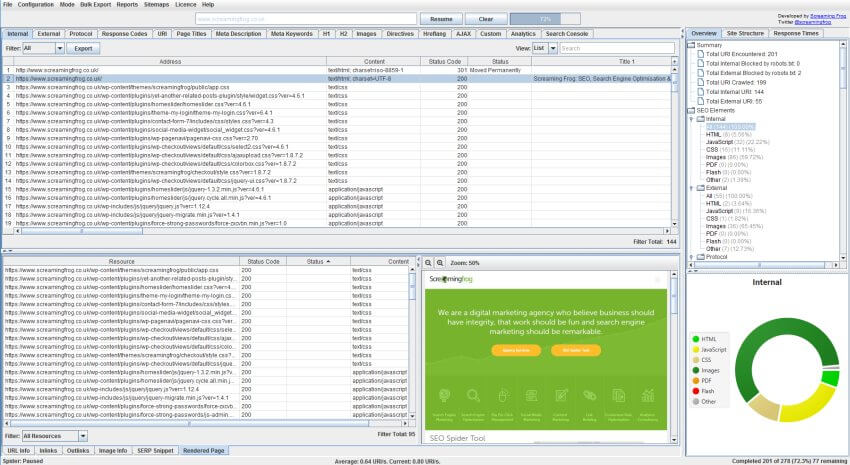
This feature is enabled by default when using the new JavaScript rendering functionality and allows you to set the AJAX timeout and viewport size to view and test various scenarios. With Google’s much discussed mobile first index, this allows you to set the user-agent and viewport as Googlebot Smartphone and see exactly how every page renders on mobile.
Viewing the rendered page is vital when analysing what a modern search bot is able to see and is particularly useful when performing a review in staging, where you can’t rely on Google’s own Fetch & Render in Search Console.
Small Update – Version 13.2 Released 4th August 2020
We have just released a small update to version 13.2 of the SEO Spider. This release is mainly bug fixes and small improvements –
- We first released custom search back in 2011 and it was in need of an upgrade. So we’ve updated functionality to allow you to search within specific elements, entire tracking tags and more. Check out our custom search tutorial.
- Sped up near duplicate crawl analysis.
- Google Rich Results Features Summary export has been ordered by number of URLs.
- Fix bug with Near Duplicates Filter not being populated when importing a .seospider crawl.
- Fix several crashes in the UI.
- Fix PSI CrUX data incorrectly labelled as sec.
- Fix spell checker incorrectly checking some script content.
- Fix crash showing near duplicates details panel.
- Fix issue preventing users with dual stack networks to crawl on windows.
- Fix crash using Wacom tablet on Windows 10.
- Fix spellchecker filters missing when reloading a crawl.
- Fix crash on macOS around multiple screens.
- Fix crash viewing gif in the image details tab.
- Fix crash canceling during database crawl load.
Small Update – Version 13.1 Released 15th July 2020
We have just released a small update to version 13.1 of the SEO Spider. This release is mainly bug fixes and small improvements –
- We’ve introduced two new reports for Google Rich Result features discovered in a crawl under ‘Reports > Structured Data’. There’s a summary of features and number of URLs they affect, and a granular export of every rich result feature detected.
- Fix issue preventing start-up running on macOS Big Sur Beta
- Fix issue with users unable to open .dmg on macOS Sierra (10.12).
- Fix issue with Windows users not being able to run when they have Java 8 installed.
- Fix TLS handshake issue connecting to some GoDaddy websites using Windows.
- Fix crash in PSI.
- Fix crash exporting the Overview Report.
- Fix scaling issues on Windows using multiple monitors, different scaling factors etc.
- Fix encoding issues around URLs with Arabic text.
- Fix issue when amending the ‘Content Area’.
- Fix several crashes running Spelling & Grammar.
- Fix several issues around custom extraction and XPaths.
- Fix sitemap export display issue using Turkish locale.
1) Google Search Analytics Integration
You can now connect to the Google Search Analytics API and pull in impression, click, CTR and average position data from your Search Console profile. Alongside , this should be valuable for Panda and content audits respectively.
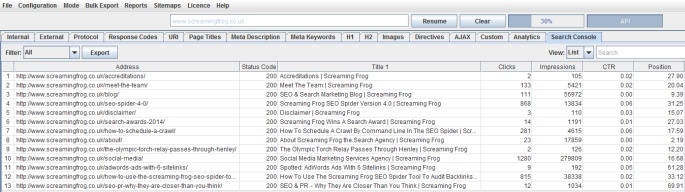
We were part of the Search Analytics beta, so have had this for some time internally, but delayed the release a little, while we finished off a couple of other new features detailed below, for a larger release.
For those already familiar with our Google Analytics integration, the set-up is virtually the same. You just need to give permission to our app to access data under ‘Configuration > API Access > Google Search Console’ –
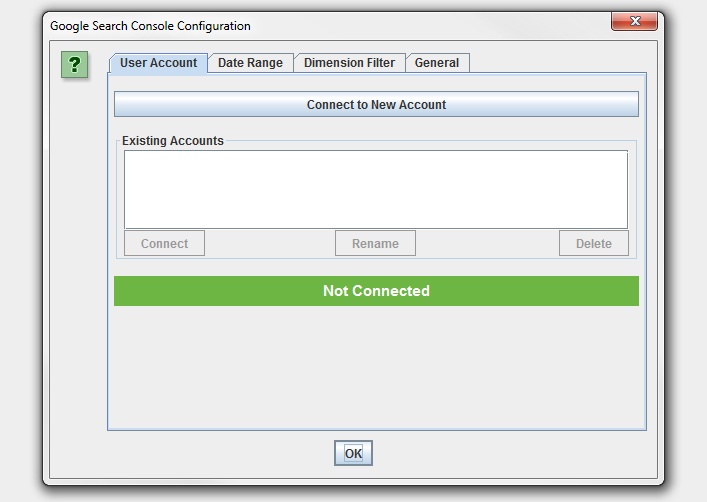
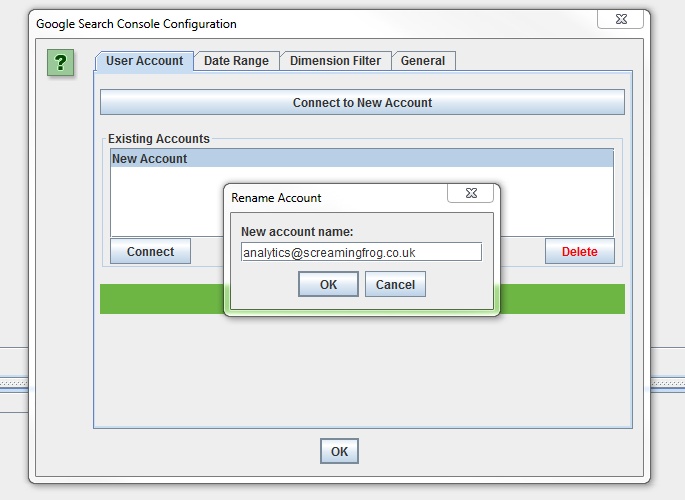
The Search Analytics API doesn’t provide us with the account name in the same way as the Analytics integration, so once connected it will appear as ‘New Account’, which you can rename manually for now.
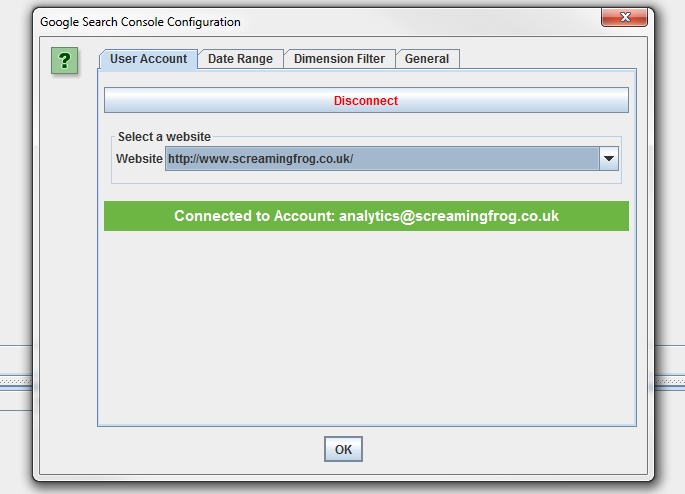
You can then select the relevant site profile, date range, device results (desktop, tablet or mobile) and country filter. Similar again to our GA integration, we have some common URL matching scenarios covered, such as matching trailing and non trailing slash URLs and case sensitivity.
When you hit ‘Start’ and the API progress bar has reached 100%, data will appear in real time during the crawl under the ‘Search Console’ tab, and dynamically within columns at the far right in the ‘Internal’ tab if you’d like to export all data together.
There’s a couple of filters currently for ‘Clicks Above 0’ when a URL has at least a single click, and ‘No GSC Data’, when the Google Search Analytics API did not return any data for the URL.
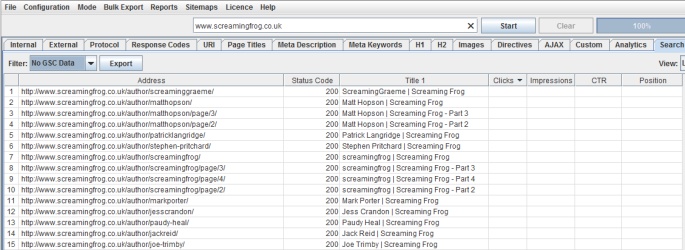
In the example above, we can see the URLs appearing under the ‘No GSC Data’ filter are all author pages, which are actually ‘noindex’, so this is as expected. Remember, you might see URLs appear here which are ‘noindex’ or ‘canonicalised’, unless you have ‘‘ and ‘‘ ticked in the advanced configuration tab.
The API is currently limited to 5k rows of data, which we hope Google will increase over time. We plan to extend our integration further as well, but at the moment the Search Console API is fairly limited.