Traceroute online — trace and map the packets path
Содержание:
- Векторизация высококонтрастных фотографий
- Разное
- ConvertHub:
- Цвета
- Создаем векторный контур
- Что такое векторизация изображения и для чего он нужен?
- ELMO[править]
- Преобразование текста в вектор с помощью модели BERT. POST-запрос¶
- Анализ цвета
- Streaming SIMD Extensions
- Векторизация: превращение слов в цифры
- YouiDraw
- Макет в кривых: какой формат
- Бесплатные аналоги Lightroom
Векторизация высококонтрастных фотографий
Из различных типов векторизации фотографий мне больше всего нравится векторизация высококонтрастных сцен, особенно содержащих силуэты. В этом разделе описаны некоторые приемы, которые позволят получить хорошие результаты при выполнении этого типа векторизации.
Чайки в силуэте
Рассмотрим следующее исходное изображение (показано в уменьшенном размере, полноразмерное изображение доступно здесь):

Очень удобно использовать режим «Логотип со смешанными краями», а не режим фото. В фоторежиме используется столько цветов, сколько алгоритм считает необходимым для достижения определенной приблизительной ошибки. Режим логотипа позволяет выбрать количество используемых цветов. Это может создать изящный эффект, если выбрать небольшое количество цветов в изображении, подобном этому.
Попробуйте настройки:
- Базовый мастер
- Логотип со смешанными краями (сглаженный)
- Низкое качество
- Фиксированные цвета (3 цвета)
Это дает следующий векторизованный результат (доступен в формате SVG здесь):

Такой результат резко контрастирует с результатом в фоторежиме (скачать здесь):

Канадские журавли в полете
Еще одна интересная фотография силуэтов птиц — это летящие канадские журавли (полноразмерная версия доступна здесь):

Опять же, ограничивая палитру, мы можем добиться интересного визуального результата. Здесь используются такие настройки: логотип со смешанными краями, средний, 5 фиксированных цветов. SVG можно скачать здесь, а предварительный результат показан ниже:

Это можно сравнить с результатом при использовании режима фотографий (SVG доступен здесь):

Одна интересная вещь, которую можно сделать с векторизованной фотографией, — это извлечь только часть фотографии для включения в другую композицию. Например, на изображении ниже показаны журавли на простом белом фоне. Их можно было бы прекрасно использовать для информационного бюллетеня организации, в названии которой встречаются слова «Канада» или «журавль».

Разное
С++ в ассемблер. Посмотреть на генерируемые инструкции можно так:
Это позволяет понять, векторизует ли уже компилятор код или нет (названия векторных инструкций начинаются с буквы v). Во многих IDE есть удобные плагины, позволяющие выяснять это для конкретных функций.
Если указать флаг , то компилятор прямо укажет на операции, которые он смог векторизовать:
Можно поменять на или , чтобы посмотреть причины, почему не получилось векторизовать другие.
Распечатать вектор. Для дебага помогает такой код:
В данном случае он выводит 4 группы по 32 бита из 128-битного вектора.
Деление. В SSE нет операции деления -ов, но есть для -ов и производных. Также нет взятия остатка от деления, что осложняет вычисления в комбинаторике.
Для деления 32-битных целых чисел их можно аккуратно скастовать к даблу, поделить так, и скастовать обратно — точности хватит, хоть это и будет медленно.
Умножение работает в несколько раз быстрее деления, и поэтому для ускорения деления -ов на известную константу \(d\) есть следующий трюк: заменить выражение \(x / d\) на \(x \cdot \frac{1}{d}\), и при этом \(\frac{1}{d}\) посчитать во время компиляции.
Для целочисленных типов такое сделать немного сложнее — нужно заменить деление на умножение и битовый сдвиг. Для этого нужно приблизить \(\frac{1}{d} \approx \frac{m}{2^s}\), подобрав «магическое» число \(m\) и степень двойки \(s\), такие что что для всех .
Можно показать, что такая пара чисел всегда существует, и компилятор сам оптимизирует деление на константу подобным образом. Вот, например, сгенерированные инструкции для деления на \(10^9 + 7\):
Здесь для умножения используется «mixed precision» инструкция , которая берёт два 64-битных числа и записывает 128-битный результат их умножения в два 64-битных регистра (lo, hi).
Для деления -ов на SSE такой способ пока что не работает: аналогичная инструкция добавилась только в AVX512.
ConvertHub:

ConvertHub is a free online JPG to vector converter that lets you convert JPG files into EPS format. Apart from EPS format, this online image converter lets you convert image into various formats like: PS, PNG, JPG, BMP, TIFF, GIF, and many more.
This website gave me best quality for JPG to EPS conversion (among free websites).
To Convert your image, you can either directly paste the URL of the image or simply upload the image from your computer. Then you can choose EPS format for conversion. Apart from this, it offers you various additional settings which you can use to customize the JPEG quality, rotate the image, etc. Before converting the raster image, you need to type in the security code displayed on the screen, to proceed with the conversion. Then click on the “Convert” button. It quickly converts the image and provides a URL from where you can easily download the vector image onto your computer. See the result below:

Цвета
| Неограниченные цвета |
| Пользовательские цвета |
В онлайн-версии это соответствует настройке цвета в разделе «Улучшение результата».
Vector Magic позволяет вам указать цвета, которые будут использоваться при трассировке вашего изображения (Пользовательские цвета). Это хорошо подходит для шумных логотипов или логотипов со слабыми контурами вокруг фигур, если вам нужны только фигуры, а не контуры.
Смысл выбора используемых цветов состоит в том, что это помогает Vector Magic создавать более чистый результат, который гарантированно не будет содержать дополнительных цветов. Это может значительно помочь в удалении дефектов с зашумленных изображений. Если в вашем логотипе 12 или меньше цветов, вам почти всегда рекомендуется использовать эту опцию.
 |
| Правильное указание цветов может означать разницу между плохим и готовым к немедленному использованию результатом |
Эту опцию также можно использовать для достижения определенного эффекта в логотипах со множеством цветов, когда исключение некоторых цветов может заставить результат выглядеть как постер.
Чтобы помочь вам выбрать цвета, Vector Magic генерирует набор предлагаемых палитр, содержащих от 2 до 12 цветов. Затем он угадывает, какая палитра наиболее вероятна, и предварительно выбирает ее для вас.
Вы можете выбрать одну из сгенерированных палитр и просто использовать ее, или начать с одной из них, а затем изменить ее в соответствии со своими потребностями. Чтобы изменить палитру, выберите цвет, который вы хотите изменить, а затем «капните пипеткой» нужный цвет из изображения.
Создаем векторный контур
У нас есть выделенная область, теперь конвертируем её в векторный контур path. Выберите любой инструмент выделения вроде Lasso Tool, Rectangular Marquee Tool или Magic Wand Tool. Кликните по области выделения правой кнопкой мыши и в появившемся меню выберите Make Work Path. В появившемся меню установите степень сглаживания Tolerance по вкусу. Зависимость простая. Чем выше цифра, тем выше сглаживание. Чем ниже цифра, тем ниже сглаживание. Высокое сглаживание означает более низкое количество векторных узелков и более неточное следование растровому контуру. В случае с моим Витрувианским человеком именно такого эффекта я и добивался.
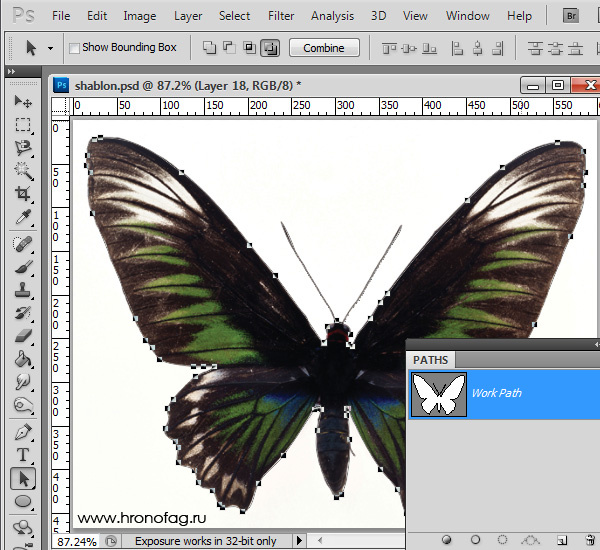
Итак, в палитре Path у нас появился рабочий контур. Если у вас нет палитры Path откройте её Windows > Path Рабочая область палитры Path похожа на десктоп или временное пристанище. На ней могут появляться разные контуры, но если вы позаботитесь о последовательном сохранении, со временем они исчезнут. Сделайте двойной клик по контуру Work Path и сохраните контур отдельно. Контуры в области Path работают так же как слои в палитре Layers. Если контур выделен, значит он активен и с ним можно работать.
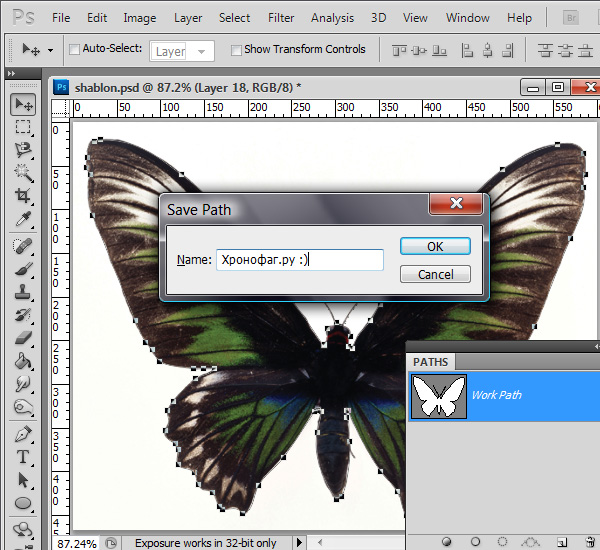
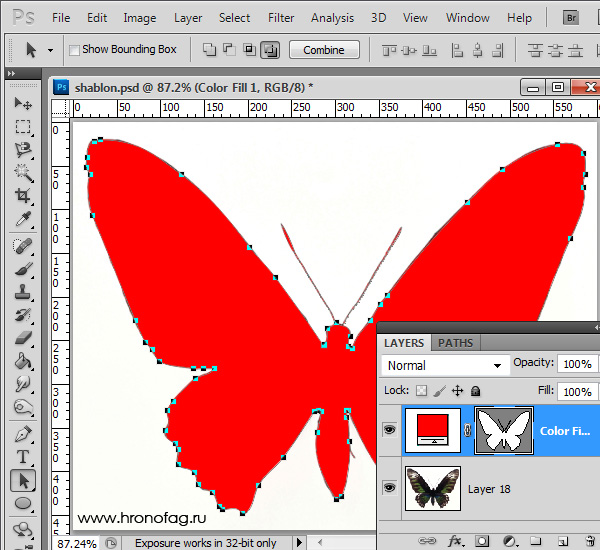
Инструменты для работы с контурами в фотошопе — Path Selection Tool и Direct Selection Tool. У нас есть контур, но нет объекта. Если вы читали серию моих заметок о векторе в фотошопе вы уже знаете, что вектор в фотошопе представлен в виде векторной маски для какого-то эффекта или графики. Еще вектор может присутствовать в виде умного слоя, ссылающегося на импортированный фаил Иллюстратора, но это оставим для другой заметки. Выделите контур инструментом Path Selection Tool или в палитре контуров Path. Нажмите Layer > New Fill Layer > Solid Color Мы создали слой заливки, которому сразу присваивается векторная маска в виде нашего контура.
Что такое векторизация изображения и для чего он нужен?

Пиксели-это наименьшие единицы изображения, они неделимы и компактно показывают определенный цвет.
Когда мы меняем эти пиксели на геометрические фигуры, которые зависят друг от друга, мы генерируем векторное изображение. Таким образом мы сможем увеличить размер изображения и получить лучшее разрешение для него, поскольку эти векторы не страдают от деформаций, которые имеет набор растровых изображений.
Наиболее часто используемые геометрические фигуры-это линии, круги, эллипсы, кривые Безье и Безигоноса . Например, если у нас есть круг, и мы хотим векторизовать его, нам нужно будет взять его в соответствии с его диаметром, центром, а также рассмотреть радиус, чтобы иметь возможность его расширить.
ELMO[править]
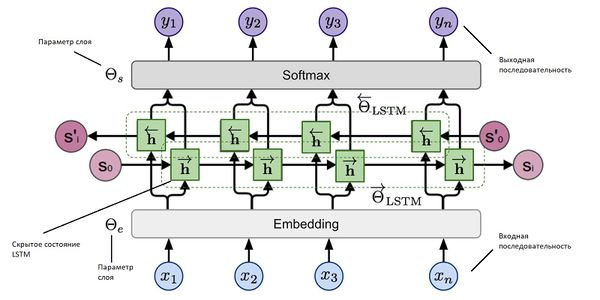
ELMO — это многослойная двунаправленная рекуррентная нейронная сеть c LSTM (рис. 5).
При использовании word2vec или fastText не учитывается семантическая неоднозначность слов.
Так, word2vec назначает слову один вектор независимо от контекста.
ELMO решает эту проблему. В основе стоит идея использовать скрытые состояния языковой модели многослойной LSTM.
Было замечено, что нижние слои сети отвечают за синтаксис и грамматику, а верхние — за смысл слов.
Пусть даны токены , на которые поделено предложение. Будем считать логарифм правдоподобия метки слова в обоих направлениях, учитывая контекст слева и контекст справа, то есть на основании данных от начала строки до текущего символа и данных от текущего символа и до конца строки.
Таким образом, модель предсказывает вероятность следующего токена с учетом истории.
Пусть есть слоев сети. Входные и выходные данные будем представлять в виде векторов, кодируя слова. Тогда каждый результирующий вектор будем считать на основании множества:
.
Здесь — входящий токен, а и — скрытые слои в одном и в другом направлении.
Тогда результат работы ELMO будет представлять из себя выражение:
.
Обучаемый общий масштабирующий коэффициент регулирует то, как могут отличаться друг от друга по норме векторные представления слов.
Коэффициенты — это обучаемые параметры, нормализованные функцией .
Модель применяют дообучая ее: изначально берут предобученную ELMO, а затем корректируют и под конкретную задачу. Тогда вектор, который подается в используемую модель для обучения, будет представлять собой взвешенную сумму значений этого векторах на всех скрытых слоях ELMO.
Преобразование текста в вектор с помощью модели BERT. POST-запрос¶
-
Адрес:
-
API требует запрос типа POST.
-
Текст должен содержаться в поле (это может быть одна строка или же вектор из нескольких строк).
-
Необязательное поле может принимать значения (для длинных текстов из нескольких предложений), или (для коротких текстов, которые не надо разбивать на предложения).
-
Результат: json с полями
-
— служебное поле
-
— , если использовалась разбивка на предложения, и в противном случае
-
— имя используемой модели BERT (необходимо для того, чтобы обеспечивать единообразность и воспроизводимость расчетов)
-
— одномерный массив из 768-мерных векторов чисел с плавающей точкой, содержащих векторизацию входного текста или текстов (если на вход была подана строка, массив будет содержать единственный 768-мерный вектор)
-
— версия алгоритма (для проверки воспроизводимости).
-
Для предотвращения непреднамеренной DOS-атаки установлено ограничение размера текста 5 килобайтами (около 2500 символов в UTF-8).
Если вам необходимо обрабатывать тексты большего объема, то рекомендуется разбивать их на фрагменты меньшего размера.
Для технической поддержки обращайтесь по адресу электронной почты support-iori@ranepa.ru.
Python 3
import requests
requests.post("https://data.iori.ranepa.ru/api/bert/encode",
json={"texts" "Мама моет раму"]},
headers={"Authorization" "Ключ_авторизации"}).json()
Curl
curl -H "Authorization: Ключ_авторизации" --data "texts='Мама моет раму'" https://data.iori.ranepa.ru/api/bert/encode
R
library(jsonlite)
library(httr)
httpResponse <- POST("https://data.iori.ranepa.ru/api/bert/encode",
add_headers("Authorization" = "Ключ_авторизации"),
accept_json(),
body = list("texts" = list("Мама моет раму")),
encode = "form")
res <- t(fromJSON(content(httpResponse, "text"))$result)
Веб-браузер
Перейдите на страницу https://data.iori.ranepa.ru/nlp/bert_vectorizer_form.html
В поле нужно ввести ваш ключ.
В поле можно ввести интересующий вас текст. Действует ограничение в 5 килобайт.
Нажмите кнопку .
Через некоторое время появится набор из 768 чисел, записанных одно за другим по 5 элементов в строке.
Пример ответа сервиса
Анализ цвета
В правой половине экрана предлагаются палитры трассировки, основанные на цветовой гамме вашего изображения. По умолчанию предлагается самая удачная (по мнению сервиса) палитра. Ниже приведены другие, от черно-белой до максимально возможной для вашего изображения. Есть возможность пополнять выбранную палитру за сет других, брать пипеткой цвета с оригинала, создавать свои варианты цветов, но всё же в пределах существующего цветового ряда.
- В левой части – ваша картинка. Её можно «зумить» и «скролить».
- Что бы выбрать пипеткой цвет, надо кликать, удерживая Ctrl.
- Постарайтесь не делать двойной клик на палитре, из-за этого автоматически начинается трассировка.
Streaming SIMD Extensions
SSE — это обобщённое название всех SIMD-инструкций для x86.
Работают они следующим образом. Помимо обычных регистров (самых близких к процессору ячеек памяти, с которыми он непосредственно работает), есть дополнительные, вмещающие не 64, а 128, 256 или даже 512 бит — в зависимости от поддерживаемой версии SSE. В эти регистры загружается последовательные блоки из памяти, над ним производится какая-то последовательность операций, и итоговый результат записывается обратно в память. Сами операции обычно логически разбивают эту булеву последовательность на блоки, например, по 32 бит, и работают уже с ними, причём одновременно.
Подобным способом довольно легко получается оптимизировать простые циклы, производящие какие-нибудь независимые друг от друга операции над векторами (массивами) — поэтому сам такой подход называют векторизацией.
Например, какое-нибудь сложение двух int-овых массивов удаётся таким образом соптимизировать в \(\frac{512}{32} = 16\) раз, если процессор поддерживает AVX512, а операции битсета — в 512 раз (реализация из STL, , SSE не использует, поэтому даже работает примерно в три раза дольше, чем просто пройтись -ом по массиву -ов).
Очень часто SSE используют для работы с действительными числами, и в этой ситуации возникает прямой trade-off между точностью вычислений и скоростью работы: например, вместо double можно использовать float, и тогда в один и тот же регистр поместится в два раза больше чисел. По этой причине в последнее время стали развиваться различные методы квантизации: перевода исходных данных в какой-то более дискретизированный формат на входе какой-нибудь процедуры (например, матричного умножения) и восстановления в исходный формат на выходе.
Конкретный набор инструкций и размеры регистров зависят от вендора и поколения архитектуры. На данный момент (лето 2019 года) большинство процессоров архитектуры x86 производит Intel, поэтому мы сконцентрируемся именно на их наборе инструкций.

Поддержка SIMD-инструкций добавлялись постепенно, сохраняя обратную совместимость. Если третий пентиум в 1999-м году умел работать с регистрами размера 128, то в самых современных i7 есть 512-битные регистры. Автор не является специалистом в проектировании микропроцессоров, но предполагает, что регистры больше 64 байт (512 бит) появятся не скоро, потому что это уже больше размера кэш-линии
Чтобы разработчикам не нужно было предоставлять отдельные оптимизированные бинарники под каждую конкретную архитектуру, информация о поддержке наборов инструкций процессором зашита в ассемблерную инструкцию , которую можно просто вызвать в рантайме и всё узнать: например так.
В компиляторе GCC есть встроенная функция , которая берёт строчку-название набора инструкций (“sse”, “avx2”, “avx512f” и т. п.) и возвращает целое число — ноль или какую-то степень двойки. Эта функция работает так: входная строка во время компиляции переводится в нужную степень двойки, которая в рантайме просто AND-ится с маской из cpuid и возвращается — всё ради эффективности.
Экономя время читателю: сервера CodeForces и большинство онлайн джаджей на момент написания статьи поддерживают AVX2, то есть умеют полноценно работать с 256-битными регистрами.
Векторизация: превращение слов в цифры
Итак, как только текст превратился в очищенную нормализованную последовательность слов, запускается процесс их векторизации – преобразования в числовые вектора . Для такой трансформации используются специальные модели, наиболее популярными из которых являются:
- cумка слов» (bag of words) – детальная репрезентативная модель для упрощения обработки текстового содержания. Она не учитывает грамматику или порядок слов и нужна, главным образом, для определения количества вхождений отдельных слов в анализируемый текст . На практике bag of words реализуется следующим образом: создается вектор длиной в словарь, для каждого слова считается количество вхождений в текст и это число подставляется на соответствующую позицию в векторе.Однако, при этом теряется порядок слов в тексте, а значит, после векторизации предложения, к примеру, “i have no cats” и “no, i have cats” будут идентичны, но противоположны по смыслу. Для решения этой проблемы при токенизации используются n-граммы .
- n-граммы – комбинации из n последовательных терминов для упрощения распознавания текстового содержание. Эта модель определяет и сохраняет смежные последовательности слов в тексте . При этом можно генерировать n-граммы из букв, например, чтобы учесть сходство родственных слов или опечаток .
- Word2Vec – набор моделей для анализа естественных языков на основе дистрибутивной семантике и векторном представлении слов. Этот метод разработан группой исследователей Google в 2013 году. Сначала создается словарь, «обучаясь» на входных текстовых данных, а затем вычисляется векторное представление слов, основанное на контекстной близости. При этом слова, встречающиеся в тексте рядом, в векторном представлении будут иметь близкие числовые координаты. Полученные векторы-слова используются для обработки естественного языка и машинного обучения .
На основе этих моделей существуют и другие, более сложные, методы векторизации текстов. Практически все эти способы Text Mining реализованы в специальных средах, например, GATE, KNIME, Orange, RapidMiner, LPU, а также специальных библиотеках на языках программирования Pythone и R .

Принцип метода Text Mining “bag of words” (сумка слов)
Еще больше интересных подробностей и прикладных знаний про Feature Extraction и другие этапы Data Preparation в нашем новом обучающем курсе для аналитиков больших данных: подготовка данных для Data Mining. Следите за новостями!
Смотреть расписание
Записаться на курс
Источники
- https://ru.wikipedia.org/wiki/Обработка_естественного_языка
- https://singularika.com/ru/nlp/natural-language-processing-terms/
- https://habr.com/ru/company/ods/blog/325422/
- https://ru.wikipedia.org/wiki/Word2vec
- http://datareview.info/article/top-5-instrumentov-dlya-text-mining/
YouiDraw
YouiDraw — векторный open source-редактор с большим количеством настраиваемых кистей. В наличии современные инструменты, например – карандаш для выполнения простых линий и контуров, а также различные средства работы с цветами.
Вы можете работать с десятками настраиваемых кистей и реалистичных текстур бумаги. В режиме редактирования точек, а также для рисования прямых линий и кривых можно использовать перо, карандаш, кисть и переключать элементы. Есть возможность объединение фигур пятью режимами: сложение, пересечение, исключение, разделение и удаление.
Можно изменять размер, масштаб и положение фигуры или текста, а также поворачивать и наклонять их так, как вам нужно. Программа очень удобная и простая. Есть инструменты для дизайна логотипов, включая готовый набор стилей, графические шаблоны и эффекты.
Основная аудитория YouiDraw – стартапы, агентства, предприятия, малый и средний бизнес. Создана программа на HTML5 Canvas, данные хранятся на Google Диске. Работать в ней можно откуда угодно. Это мощный веб-инструмент для дизайна векторной графики. Интегрируется программа практически с любым веб-приложением.
Макет в кривых: какой формат
Среди распространенных векторных форматов обычно используются cdr, ai, eps, svg и pdf.
Если осуществляется создание макета в кривых – формат будет соответствовать типичным требованиям, предъявляемым современной типографией. Кривыми называют состояние шрифта, соответствующее векторному макету. Если не позаботиться о таком виде создания шрифта, его можно редактировать только при наличии на компьютере. При пользовании другим ПК возможности для редактирования файла будут ограниченными. Иногда осуществляют замену правильных шрифтов другими, что приводит к изменению вида будущего издания.
Сегодня принята разработка макета в кривых, какой бы формат продукции не был запланирован заказчиком. В такой ситуации полиграфистам не придется заниматься редактированием макета, и не возникнет проблем при печати. Векторный редактор соответствует даже растровым файлам, хотя для передачи в печать понадобится подготовка, соответствующая требованиям типографии. При подготовке макета в кривых, какой формат разрабатывается для реальной печати следует уточнить у типографии, во избежание неприятных последствий при предпечатной обработке. Дизайнеру всегда проще работать с исходником либо самостоятельно заниматься подготовкой макета под ключ.
Бесплатные аналоги Lightroom
Многие думают, что для обработки фотографий можно использовать только Фотошоп, тогда как в большинстве случаев лучше с этим справится именно Lightroom. Ниже рассмотрим некоторые альтернативы Lightroom для работы. Они достаточно неплохие, хоть и не дотягивают до полной функциональности и гибкости оригинальной программы. Тем не менее для простых задач этого вполне хватит.
Raw Therapee
Raw Therapee является одним из лучших бесплатных решений в качестве замены Лайтрума. Здесь есть все необходимые функции + достаточно быстро выходят новые обновления. Основные плюсы: эффективность, универсальность и высокое качество изображений. Подходит для Win / Mac / Linux.
Darktable
Если на просьбу назвать лучший бесплатный аналог Lightroom вам не упомянут Raw Therapee, то обязательно скажут о Darktable. Этот мощный программный продукт с открытым кодом для работы с Raw изображениями имеет множество полезных функций
При этом вы найдете здесь достаточно простой легкий интерфейс и хорошую навигацию, что в процессе обработки фоток немаловажно. Единственная сложность почему многие не могут использовать Darktable — отсутствие поддержки Windows ОС
Photoscape
Аналог Лайтрума для Win / Mac Photoscape мы приводим на крайний случай, если вдруг вам не понравились предыдущие два. Программа содержит ряд полезных функций по обработке фото (редактор, конвертер RAW в JPG и т.п.), однако последняя версия была выпущена в далеком 2014 год. Поэтому все же лучше внимательно изучить Raw Therapee или Darktable.