Описание методов
Содержание:
- await this.request(method, url[, queryParams][, opts])#
- Обзор парера картинок DuckDuckGo Images#
- Парсинг сайтов
- Десктопные и облачные парсеры
- Парсеры поисковых систем#
- Проблема урлов картинок и ссылок
- Скачивание картинок по ссылке#
- Парсер картинок с сайта
- Поищите XHR запросы в консоли разработчика
- Поищите JSON в HTML коде страницы
- Отрендерите JS через Headless Browsers
- Возможные настройки#
- Парсите HTML теги
- URL картинок
- Интегрировано с
- Парсите страницы сайтов в структуры данных
await this.request(method, url[, queryParams][, opts])#
awaitthis.request(method, url, queryParams, opts)
Скопировать
Получение HTTP ответа по запросу, в качестве аргументов указывается:
- — метода запроса (GET, POST…)
- — ссылка для запроса
- — хэш с get параметрами или хэш с телом post-запроса
- — хэш с опциями запроса
Если используется метод POST, то тело запроса можно передать двумя способами:
просто перечислив названия переменных и их значения в queryParams. Например:
{
key set.query,
id1234,
type ‘text’
}
Скопировать
через переменную body в opts. Например:
body ‘key=’ + set.query + ‘&id=1234&type=text’
Скопировать
— массив условий для проверки получаемого контента, если проверка не проходит, то запрос будет повторен с другим прокси.
Возможности:
- использование в качестве условий строк (поиск по вхождению строки)
- использование в качестве условий регулярных выражений
- использование своих функций проверок, в которые передаются данные и хедеры ответа
- можно задать сразу несколько разных типов условий
- для логического отрицания поместите условие в массив, т.е. означает что запрос будет считаться успешным, если в полученных данных содержится подстрока и при этом регулярное выражение не находит совпадений на странице
Для успешного запроса должны пройти все указанные в массиве проверки
let response =awaitthis.request(‘GET’, set.query,{},{
check_content
<\/html>|<\/body>,
‘XXXX’,
‘</html>’,
(data, hdr)=>{
return hdr.Status==200&& data.length>100;
}
});
Скопировать
— автоматическое определение кодировки и преобразование в utf8
Возможные значения:
- — на основе заголовков, тегов meta и по содержимому страници (оптимальный рекомендуемый вариант)
- — указывает что документ в кодировке utf8
- — любая другая кодировка
— хэш с заголовками, название заголовка задается в нижнем регистре, можно указать в т.ч. cookie
Пример:
headers{
accept’image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8′,
‘accept-encoding»gzip, deflate, br’,
cookie’a=321; b=test’,
‘user-agent»Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36’
}
Скопировать
— позволяет переопределить порядок сортировки заголовков
— максимальное число переходов по редиректам, по умолчанию 7, используйте 0 для отключения перехода по редиректам
— число попыток выполнения запроса, по умолчанию берется из настроек парсера
— перечень кодов HTTP ответов, которые парсер будет считать удачными, по умолчанию берется из настроек парсера. Если указать то все ответы будут считаться удачными.
Пример:
parsecodes{
2001,
4031,
5001
}
Скопировать
— таймаут ответа в секундах, по умолчанию берется из настроек парсера
— определяет использовать ли компрессию (gzip/deflate/br), по умолчанию включено (1), для выключения нужно задать значение
— максимальный размер ответа в байтах, по умолчанию берется из настроек парсера
— хэш с куками. Пример хэша:
«cookie_jar»{
«version»1,
«.google.com»{
«/»{
«login»{
«value»»true»
},
«lang»{
«value»»ru-RU»
}
}
},
«.test.google.com»{
«/»{
«id»{
«value»155643
}
}
}
}
Скопировать
— указывает на номер текущей попытки, при использовании этого параметра встроенный обработчик попыток для данного запроса игнорируется
— автоматическая эмуляция заголовков браузера (1 — включено, 0 — выключено)
— переопределяет использование прокси для отдельного запроса внутри JS парсера поверх глобального параметра Use proxy (1 — включено, 0 — выключено)
— отключает добавление Extra query string к урлу запроса (1 — включено, 0 — отключено)
— позволяет скачать файл напрямую на диск, минуя запись в память. Вместо file указывается имя и путь под каким сохранить файл. При использовании этой опции игнорируется все, что связано с data (проверка контента в check_content, response.data будет пустой и т.д.).
— определяет передавать (1) или нет () в ответе data/pages[], может использоваться для оптимизации
— определяет возвращать data как строку String () или как объект Buffer (1), по умолчанию возвращается строка String
— автоматический обход JavaScript защиты CloudFlare используя браузер Chrome (1 — включено, 0 — выключено)
— позволяет переходить по редиректам, объявленным через HTML мета тег:
<metahttp-equiv=»refresh»content=»time; url=…»/>
Скопировать
– позволяет передавать для https соединений
Обзор парера картинок DuckDuckGo Images#
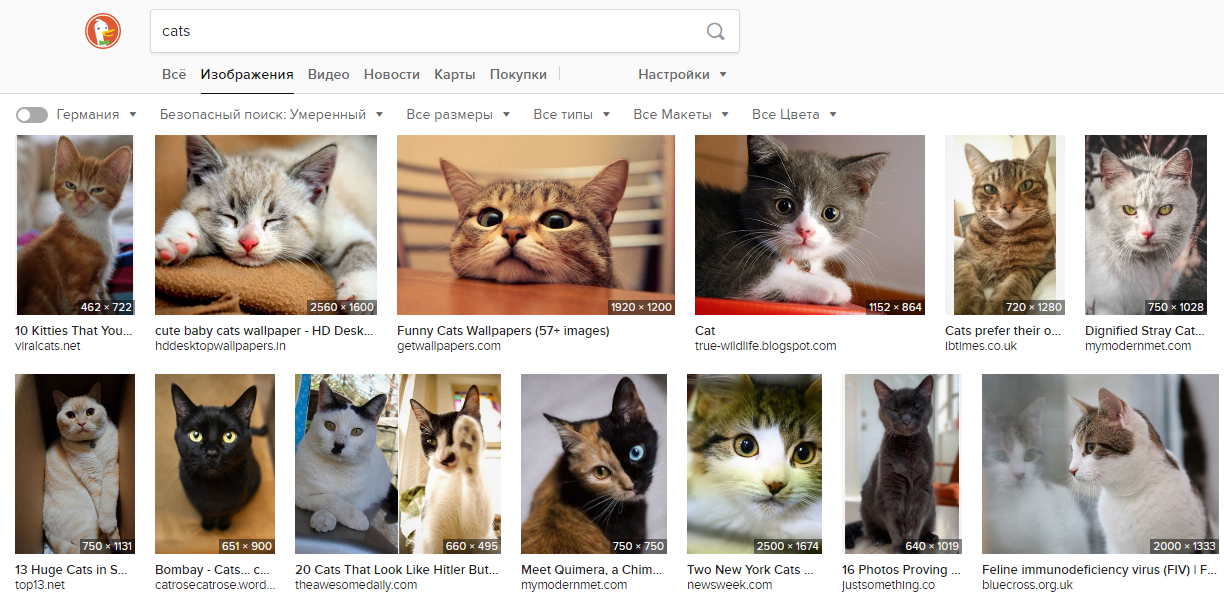
Парсер изображений поисковой выдачи DuckDuckGo. Благодаря парсеру SE::DuckDuckGo::Images вы сможете получать базы ссылок изображений или изображений, готовых для дальнейшего использования. Вы можете использовать запросы в том же виде, в котором вы вводите их в поисковую строку DuckDuckGo
Функционал A-Parser позволяет сохранять настройки парсинга парсера DuckDuckGo для дальнейшего использования (пресеты), задавать расписание парсинга и многое другое. Вы можете использовать автоматическое размножение запросов, подстановку подзапросов из файлов, перебор цифро-буквенных комбинаций и списков для получения максимально возможного количества результатов.
Сохранение результатов возможно в том виде и структуре которая вам необходима, благодаря встроенному мощному шаблонизатору Template Toolkit который позволяет применять дополнительную логику к результатам и выводить данные в различных форматах, включая JSON, SQL и CSV.
Парсинг сайтов
-
Урок № Учебник по парсингу сайтов
-
Урок № Парсинг сайтов регулярными выражениями PHP
-
Урок № Работа с библиотекой CURL в PHP
-
Урок № Работа с библиотекой phpQuery в PHP
-
Урок № Поэтапный парсинг и метод паука
-
Урок № Парсинг картинок на PHP
-
Урок № Практика по парсингу сайтов
-
Урок № Автоматическая отправка форм на PHP
-
Урок № Автоматическая авторизация на сайте
-
Урок № Парсинг JavaScript и AJAX на PHP
-
Урок № Обход капчи при парсинге на PHP
-
Урок № Обход защиты от парсинга
-
Урок № Автоматизация парсинга на PHP
-
Урок № Многопоточный парсинг на PHP
-
Урок № Практика по парсингу сайтов
-
Урок № Работа с XML в PHP
-
Урок № Библиотеки для парсинга сайтов на PHP
-
Урок № Полезные штуковины для парсинга
-
Урок № Парсинг сайтов с помощью selenium на PHP
-
Урок № Практика по парсингу сайтов
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
- Import.io,
- Mozenda (доступна также десктопная версия парсера),
- Octoparce,
- ParseHub.
Из русскоязычных облачных парсеров можно привести такие:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
- ParserOK,
- Datacol,
- Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |
Проблема урлов картинок и ссылок
Как вам должно быть известно, существуют абсолютные пути и относительные. Пример: ссылка http://site.ru/folder/subfolder/page.html — абсолютная, а ссылка folder/subfolder/page.html — относительная.
Учтите, что то, куда ведет относительная ссылка, зависит от той страницы, где она расположена. Давайте разберемся более подробнее.
Пример: мы парсим страницу сайта, url страницы http://site.ru/folder/subfolder/index.html.
На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/77270.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/folder/subfolder/image.png. Давайте разберем все возможные варианты.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/75516.png» — с начальным слешем (эта ссылка тоже абсолютная, только без http в начале). В этом случае реальный абсолютный путь к картинке такой: http://site.ru/image.png.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/59157.png».
В этом случае реальный абсолютный путь к картинке такой: http://site.ru/folder/subfolder/images/image.png.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/45053.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/images/image.png.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/7676.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/folder/image.png, так как конструкция ../ поднимает нас на папку выше.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/41032.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/image.png, так как конструкция ../../ поднимает нас на две папки выше.
Пусть url страницы http://site.ru/folder/subfolder/index.html. На этой странице расположена картинка src=»https://steptosleep.ru/wp-content/uploads/2018/06/80277.png». В этом случае реальный абсолютный путь к картинке такой: http://site.ru/folder/image.png, так как конструкция ../ поднимает нас на две папки выше.
Думаю, вам понятно, что в данном случае разницы между картинками и ссылками никакой нет — все пути строятся одинаково. То же самое относится к путям к CSS файлам, если они вам вдруг понадобятся (всякое бывает).
В общем, я думаю, общая логика ясна.
Скачивание картинок по ссылке#
A-Parser позволяет использовать цепочку заданий, по завершению первого, начнется выполнение второго, в качестве запросов для второго задания будут ссылки из первого
Скачать пример
eJyNVstS2zAU/ZWOJovQBsdZdOMNE2jT0qGEQliFdEaNb4xAlowkE1KTf++V7PiR
GpOdJd2n7jnHyoih+lFfKdBgNAnmGUncNwnINykjDh/OYxrBhy9yLbikISgyIAlV
GpQ1n5Obr0GQWwaBM9VoEMKKptyQQUbMJgEMJp9BKRYCHrIQ14mSLxsFRjHn8Ex5
as1Gvk+2HV4YfylTYSqXUYd5KGPKRC38er32Ilest5RxVyauam5dhhE/0PC+bgii
y1Szv3Bg1KXk8tBSFYvujT7Q2G0fZopYSAyLm+aLxYAgkhAFeiJVTC2iesnIK+BV
Ht7QZ5hJPFwxDtX2BFeXNLaxeiE1YE+9lQvUP/LMi41Aw5AZJgXleQYLyCrrrWBP
rhaNIBMR2uPSwm2icPTYILggdnOzq3BOem5NMEzq/H/lPiRYUa5hQDSWO6FYTLh/
wgwoaqSaJrYm3M+IFGPOL+AZeGXm4p+mjCOV9HiFTueFY7vJ9L8Y27LFeiqcyVph
DWUUtzqd/qy8QnkhI0uLP9g3ZzEzuNZnjk8B8XHzESAp7+1S4k4sFZRpjEqhTI6a
kYCw86+mNk6qrUYXjck0N5dSrFg0LTC1s0zFDIVpKs5knHCwbZFcXZpKlGq4rgAz
1sVQ7KIsdz/UmUto72GnUsRIyfWPm7zwRDHE42dbbozXWq+huNol5fz2+qJRXYUv
x0rHjiUCN5IIJ+zJ8qeum5dgguD7bHbVlEsFEby4CMKAMMeWcoH38YTZ5of9RESv
DwmcRK8RWx25i0f7Wc5LZjmhFN0UxLGN5SfLVBsZ5zdVTstqElA3iN1WEWjFaY2h
lhaWK66FHcGFFFDFR3YaNw/poOI0Qeh6ppxsuV2RRUgDTynlTa2oeO9a1sOckZ5I
4+NeVnyjwdazapKHbUGLSDl/A+Rt+G2VhkOQ0wlAv+KckO8K1r4SvoGyOqjaJRb1
krYQMCNapmppw+QiZ3Fvh2uvkywGJfaG/fnv4eLT0d2d1z8JmpDrtWCuAEHuvl0M
qidEG2VbpGJPav02ISpZ2aLAfp17+3RuKJj/hgjt/zPcuN5TdL9bzfePG0rub9v0
xe/4H7XrZNePwK//BGxCN4PQvpkW5SOufPplbU+5IEO3SqpwiesHfZX7WpQXNphV
O+aPtv8AjbCG+g==
Скопировать
Парсер картинок с сайта
С этой целью может быть использована специальная программа для скачивания фото целыми альбомами – VKAlbumSaver.
Используя эту программу, можно скачивать любые альбомы целиком, или же указать диапазон требуемых фотографий. Программа позволяет сохранить скачанные фотографии в заданной папке и определить имя для этой папки.
Не все знают, как можно сохранить свои же фото из Инстаграма на собственный компьютер (в самом Инстаграме такой опции не предусмотрено). Для этой цели удобно использовать утилиту Instaport. Чтобы эта программа для скачивания фото из приложения для обмена фотографиями на ваш компьютер заработала, нужно зайти на сервис Instaport.me и просто авторизовать собственный аккаунт на Инстаграм. После авторизации становится доступной опция загрузки на ваш компьютер всех ваших фото.
Поищите XHR запросы в консоли разработчика
 Кабина моего самолета
Кабина моего самолета
Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).

Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ️Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
-
Открывайте вебстраницу, которую хотите спарсить
-
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
-
Открывайте вкладку Network и кликайте на фильтр XHR запросов
-
Обновляйте страницу, чтобы в логах стали появляться запросы
-
Найдите запрос, который запрашивает данные, которые вам нужны
-
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.
 Кнопка, которую я искал месяцы
Кнопка, которую я искал месяцы
Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? Нет!
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен!
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
 Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.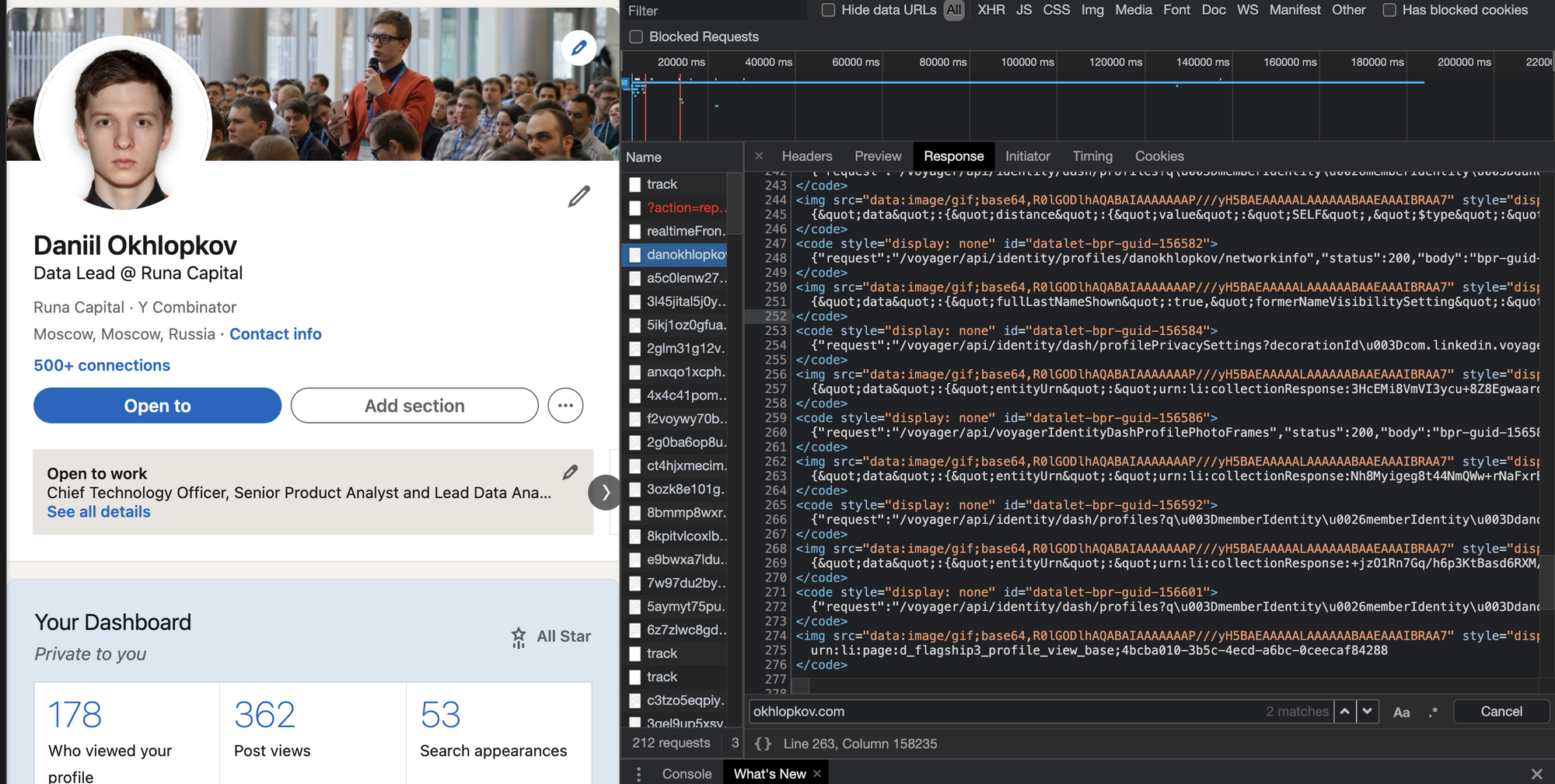 И наш любимый (у парсеров) Linkedin!
И наш любимый (у парсеров) Linkedin!
Алгоритм действий такой:
-
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
-
Внизу ищите длинную длинную строчку с данными.
-
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто.
-
Вырезаете JSON из HTML любыми костылямии (я использую ).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
Selenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
Заметьте фложок . Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Возможные настройки#
important
| Параметр | Значение по умолчанию | Описание |
|---|---|---|
| Pages count | 10 | Количество страниц для парсинга |
| Google domain | www.google.com | Домен Гугла для парсинга, поддерживаются все домены |
| Results language | Auto (Based on IP) | Выбор языка результатов(параметр lr=) |
| Search from country | Auto (Based on IP) | Выбор страны откуда осуществляется поиск(гео-зависимый поиск, параметр gl=) |
| Interface language | English | Возможность выбора языка интерфейса Google, для максимальной идентичности результатов в парсере и в браузере |
| Size | Any size | Выбор размера изображений |
| Color | Any color | Выбор цвета изображений |
| Usage rights | Not filtered by license | Лицензия на использование изображений |
| Type | Any type | Выбор типа изображений |
| Serp time | All time | Время серпа (временно-зависимый поиск, параметр tbs=) |
| Util::ReCaptcha2 preset | default | Пресет парсера Util::ReCaptcha2 Util::ReCaptcha2 Необходимо предварительно настроить парсер Util::ReCaptcha2 — указать свой ключ доступа и другие параметры, после чего выбрать созданный пресет здесь |
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.

URL картинок
Для того чтобы добавить изображение, необходимо прописать тег и и внутри атрибута прописать путь к файлу.
Зная это мы с легкостью может сделать обратное, нам нужно достать из тега значение этого атрибута.
Важный момент:
- Пути к файлу бывают 2 видов. Абсолютный и относительный.
- Абсолютный путь имеет вид – http://prog-time.ru/wp-content/uploads/2018/10/SHpargalka-po-git-720×414.jpg. Такой путь путь имеет протокол и является полным, начинающимся от корня сайта.
- Относительный путь имеет вид – /uploads/2018/10/SHpargalka-po-git-720×414.jpg . Относительный путь имеет только часть адреса, который может быть написан по разному.
Основные правила написания относительного пути:
Если мы находимся на странице http://prog-time.ru/wp-content/uploads/2018/10/index.php и хотим забрать картинку с адресом img.png. Полный адрес к изображению будет http://prog-time.ru/wp-content/uploads/2018/10/img.png
Если мы находимся на странице http://prog-time.ru/wp-content/uploads/2018/10/index.php и хотим забрать картинку с адресом /img.png. Полный адрес к изображению будет http://prog-time.ru/img.png. Знак слеша в адресе означает что путь начинается от корневой директории.
Если мы находимся на странице http://prog-time.ru/wp-content/uploads/2018/10/index.php и хотим забрать картинку с адресом images/img.png. Полный адрес к изображению будет http://prog-time.ru/wp-content/uploads/2018/10/images/img.png.
Если мы находимся на странице http://prog-time.ru/wp-content/uploads/2018/10/index.php и хотим забрать картинку с адресом ../img.png. Полный адрес к изображению будет http://prog-time.ru/wp-content/uploads/2018/10/img.png . Если бы не было двух точек и слеша, путь был бы такой http://prog-time.ru/wp-content/uploads/2018/10/img.png , но если их поставить, то они поднимают нас на папку выше и путь становится таким http://prog-time.ru/wp-content/uploads/2018/10/img.png .
Интегрировано с
Zapier автоматически перемещает данные между вашими веб-приложениями.
Zapier |
Использование
Tableau — Business Intelligence платформа, лидер рынка платформ для бизнес-аналитики.
Tableau |
Использование
Еще один сервис с помощью которого вы сможете обходить капчи любой сложности.
rucaptcha |
Использование
С помощью сервиса Anti-captcha вы можете обходить капчи любой сложности.
Anti-captcha |
Использование
Luminati, это прокси сервис, который позволит вам иметь любое количество IP адресов.
Luminati |
Использование
С помощью сервиса Death by Captcha вы можете обходить капчи любой сложности.
Deathbycaptcha |
Использование
Proxy-Sellers предоставляют прокси из более чем 100 сетей и 300 различных подсетей.
Proxy-Seller |
Использование
Инфраструктура поддерживает миллиарды скраперов каждый месяц.
Blazing SEO |
Использование
Парсите страницы сайтов в структуры данных
Что такое Диггернаут и что такое диггер?

Диггернаут — это облачный сервис для парсинга сайтов, сбора информации и других ETL (Extract, Transform, Load) задач. Если ваш бизнес лежит в плоскости торговли и ваш поставщик не предоставляет вам данные в нужном вам формате, например в csv или excel, мы можем вам помочь избежать ручной работы, сэкономив ваши время и деньги!
Все, что вам нужно сделать — создать парсер (диггер), крошечного робота, который будет парсить сайты по вашему запросу, извлекать данные, нормализовать и обрабатывать их, сохранять массивы данных в облаке, откуда вы сможете скачать их в любом из доступных форматов (например, CSV, XML, XLSX, JSON) или забрать в автоматическом режиме через наш API.
Какую информацию может добывать Диггернаут?

- Цены и другую информацию о товарах, отзывы и рейтинги с сайтов ритейлеров.
- Данные о различных событиях по всему миру.
- Новости и заголовки с сайтов различных новостных агентств и агрегаторов.
- Данные для статистических исследований из различных источников.
- Открытые данные из государственных и муниципальных источников. Полицейские сводки, документы по судопроизводству, росреест, госзакупки и другие.
- Лицензии и разрешения, выданные государственными структурами.
- Мнения людей и их комментарии по определенной проблематике на форумах и в соцсетях.
- Информация, помогающая в оценке недвижимости.
- Или что-то иное, что можно добыть с помощью парсинга.
Должен ли я быть экспертом в программировании?

Если вы никогда не сталкивались с программированием, вы можете использовать наш специальный инструмент для построения конфигурации парсера (диггера) — Excavator. Он имеет графическую оболочку и позволяет работать с сервисом людям, не имеющих теоретических познаний в программировании. Вам нужно лишь выделить данные, которые нужно забрать и разместить их в структуре данных, которую создаст для вас парсер. Для более простого освоения этого инструмента, мы создали серию видео уроков, с которыми вы можете ознакомиться в документации.
Если вы программист или веб-разработчик, знаете что такое HTML/CSS и готовы к изучению нового, для вас мы приготовили мета-язык, освоив который вы сможете решать очень сложные задачи, которые невозможно решить с помощью конфигуратора Excavator. Вы можете ознакомиться с документацией, которую мы снабдили примерами из реальной жизни для простого и быстрого понимания материала.
Если вы не хотите тратить свое время на освоение конфигуратора Excavator или мета-языка и хотите просто получать данные, обратитесь к нам и мы создадим для вас парсер в кратчайшие сроки.