Лучшие программы для мониторинга температур компьютера
Содержание:
HWiNFO
 Небольшая утилита HWiNFO способна вывести на экран все основные параметры компьютера и его компонентов, а также отслеживать температуру и напряжение с датчиков устройств в режиме реального времени. По заявлению разработчиков она отличается повышенной стабильностью работы и высокой точностью измерений диагностирующих параметров. За утилиту платить необязательно, разработчик принимает лишь пожертвования.
Небольшая утилита HWiNFO способна вывести на экран все основные параметры компьютера и его компонентов, а также отслеживать температуру и напряжение с датчиков устройств в режиме реального времени. По заявлению разработчиков она отличается повышенной стабильностью работы и высокой точностью измерений диагностирующих параметров. За утилиту платить необязательно, разработчик принимает лишь пожертвования.
Главным качеством HWiNFO выступает стабильность работы на слабых системах с устаревшими версиями Windows. Данный софт запустится даже на Win XP, не говоря уже о современных «десятках». Вторым достоинством является подробная отчетность о состоянии ПК в момент проверки и предоставление подробных сведений о его параметрах. Простой поиск каждого устройства обеспечен иерархической структурой иконок с описанием в левой части окна. Имеющиеся данные легко сохранить в тестовый файл по кнопке «Save Report». Кроме проверки компьютера HWiNFO имеет подпрограмму для обновления BIOS материнской платы и драйверов устройств.
Интерфейс ПО HWiNFO выполнен в привычном стиле Windows и удобен в использовании. В верхней части окна расположена панель с иконками самых часто используемых функций. Во вкладке «Program» есть большое количество настроек режимов проверки и управления драйверами.
Преимущества:
- простота и подробность отчета;
- удобное управление и настройка;
- высокая точность измерений показаний датчиков;
- обновление BIOS и драйверов;
- полностью бесплатное ПО.
Недостатки:
нет тестов для проверки стабильности и производительности системы.
SIEM
Переход от LM к системам класса Security Information and Event Management требуется в двух случаях:
-
Необходимо оповещение операторов о подозрениях на инциденты (далее — инциденты) в режиме близком к реальному времени. К этой опции должны прилагаться сотрудники, работающие в том же режиме — 24х7.
-
Необходимо выявление последовательностей разнородных событий. Это уже не просто фильтрация и агрегация, как в LM или Sigma (на текущий момент).
Дополнительно вы получите:
-
Правила «из коробки», которые хороши в качестве примеров или отправной точки. Или после глубокой доработки и настройки.
-
Историческую корреляцию, совмещающую преимущества SIEM (структура корреляционного запроса) и LM (работа с данными на всю глубину). Быстрое тестирование нового правила на исторических данных, проверка только что пришедшего IOC, который обнаружен две недели назад, запуск правил с большими временными окнами в неурочное время – всё это применения данной функции. Она может быть частью базового решения, требовать отдельных лицензий или вовсе отсутствовать.
-
Второстепенные для одних, но критичные для других функции. Иное представление данных на дашбордах, отправка отчётов в мессенджер, гибкое управление хранением событий и т.д. Производитель стремится оправдать скачок цены от LM к SIEM.
Задачи на этом этапе следующие:
Создание логики детектирования всех интересных вам инцидентов. Без автоматизации вам приходилось выбирать только самые критичные
Сейчас можно учесть всё действительно важное. Главный вопрос – как на таком потоке выстроить реагирование.
Уменьшение ЛПС и ЛОС путём обогащения данных – добавления информации из внешних справочников, изменения пороговых значений, дробления правил по сегментам, группам пользователей и т.д
Возросший объём статистики по работе сценариев улучшает качество их анализа.
Обе задачи решаем итерационно. Хороший показатель – 15 инцидентов на смену аналитика. Достигли его – закручиваем гайки дальше.
Начинаем оценивать эффективность расследования – время на приём в работу инцидента, время на реагирование, время на устранение последствий и т.д. И пытаться этой эффективностью управлять – что мешает работать быстрее, где основные задержки?
Результаты использования SIEM:
Выявление инцидентов происходит в автоматическом режиме, возможно обнаружение и корреляция цепочек разнородных событий.
Рост числа типов инцидентов
Аналитик переключает внимание с обнаружения на расследование и реагирование. При этом не стоит забывать про Threat Hunting – этот метод остаётся лучшим для определения новых для вас угроз.
Какой шаг сделать дальше? Тут лучших практик нет. Следующие этапы могут идти последовательно в любом порядке, параллельно или вовсе отсутствовать.
Стахановец
Система контроля «Стахановец» собирает, обрабатывает и анализирует информацию с компьютеров сотрудников организации, повышая информационную безопасность компании и эффективность бизнес-процессов. Для разных групп пользователей в программе предусмотрены собственные режимы сбора данных.
- учет времени работы сотрудников;
- контроль активности;
- анализ клавиатурного почерка;
- перехват изображений и аудио;
- распознавание речи и отслеживание аудио переговоров в мессенджерах;
- анализ эффективности работы сотрудников;
- информация о контактах сотрудника внутри организации;
- перехват переписки в мессенджерах, соцсетях и электронной почте;
- мониторинг посещенных сайтов;
- перехват информации, выводимой за пределы компьютера.
Обо всех подозрительных действиях сотрудника программа отправляет руководителю соответствующие оповещения. «Стахановец» легко встраивается в любую инфраструктуру и обладает минимальными системными требованиями, поэтому его работа не замедляет другие процессы на ПК.
Для владельцев крупного бизнеса разработана инновационная версия программы — «Стахановец Pro», основанная на искусственном интеллекте и уже обученной нейросети. Система предлагает работодателям применять для контроля новейшие функции, например, распознавание лиц с вэб-камеры компьютера.
При этом программа может работать более чем на 10 000 клиентских машинах с минимально возможным потреблением ресурсов сервера.

Настройка Zabbix
Предупреждение: Zabbix настраивал в первый раз, как и Linux Mint (так как Zabbix под Windows нет) 🙂 autoconfautomakelibtoolpkg-configlibzbxmodbusХабреGitHub
libzbxmodbusetc/zabbix/zabbix_server.conf/dev/ttyUSB0lsusb
Шаг 1. Создаем узел сети и группу, в которые наши узлы будут входить (например, узел — «Контроль состояния окружающей среды» и группу — «Инженерная инфраструктура»):
Настройка > Узлы сети > Создать узел сети > Вводим наши названия > Добавить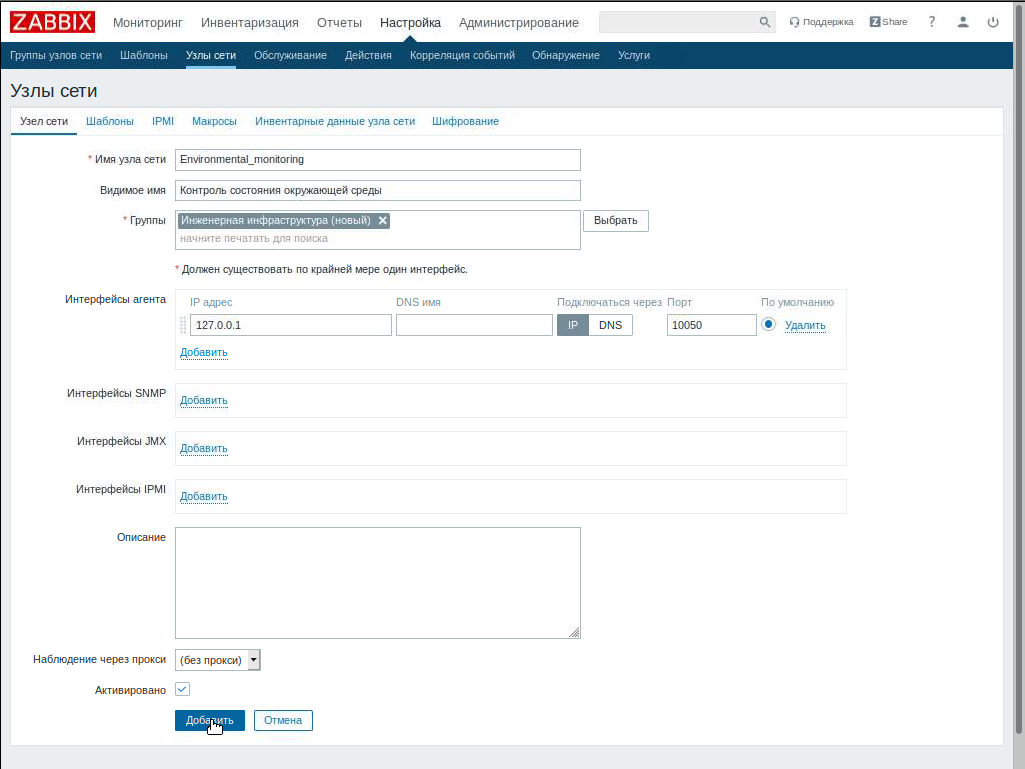
Шаг 2. Создадим элементы данных. В статье рекомендуется создавать шаблоны, но так как у нас система не содержит повторяющихся элементов, поэтому пропущу этот шаг. Например, если бы у нас было несколько кондиционеров, подключаемых по Modbus, то можно было бы воспользоваться функционалом системы.
Настройка > Узлы сети > В строке содержащей название нашего узла «Контроль состояния окружающей среды» нажимаем на «Элементы данных» > в появившемся окне нажимаем «Создать элемент данных».
Начинаем «забивать» наши датчики: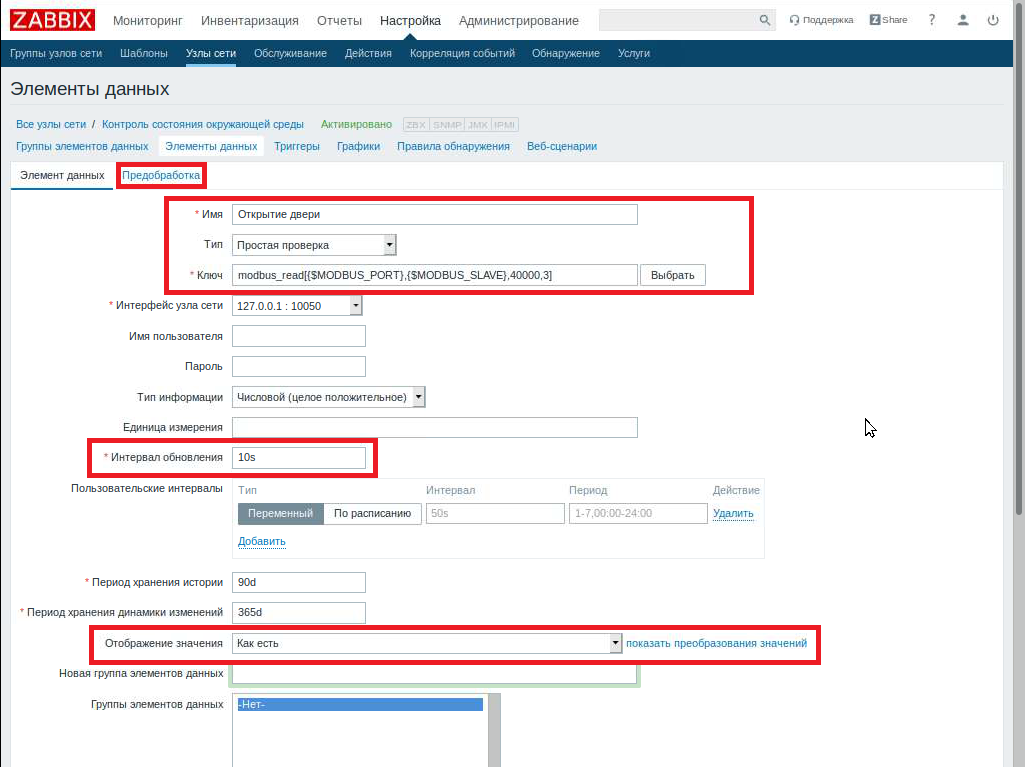
Небольшие нюансы:
- в статье используется синтаксис функции «modbus_read_registers», а по описанию GitHub «modbus_read» — второй вариант короче и работает;
- можно вместо макросов {$MODBUS_PORT} и {$MODBUS_SLAVE} указывать порт в виде /dev/ttyUSB0 и «11», но это будет неудобно, если потом потребуется изменить порт USB или адрес С2000-ПП;
- в документации указано, что для запроса состояния зоны (столбец «№ зоны Modbus») на С2000-ПП необходимо обратиться на: «адрес регистра 40000+М, где М = (№ зоны –1)» — вот так ход: «№ зоны минус 1»;
- не делайте очень частый опрос по времени: С2000-ПП начнет возвращать ошибку «exception error 15» — прибор не успевает подготавливать данные (выражается это в постоянном свечении индикатора на приборе) ;
- для температуры и влажности забираются данные с регистрами 3000-…
- в окне «Элементы данных» также есть нужная закладка «Предобработка». Тут можно отредактировать, что будет показываться «в итоге». Температура и влажность, получается из считываемых значений, которые необходимо разделить на 256: «Пользовательский множитель»- 0,0039 (т.е. 1/256);
- Для дискретных герконов, датчиков протечки и т.п. нужно еще использовать «Отображение значений», связано это со способом предоставления информации.
914835188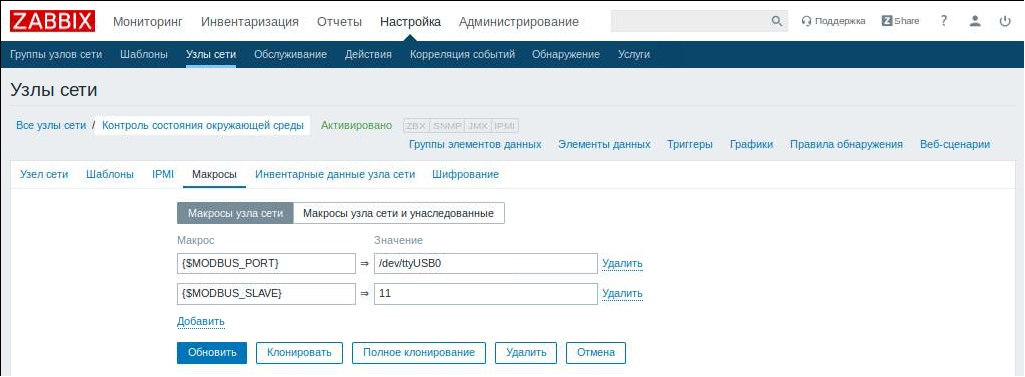

Speccy
 Первая на обзоре в данной статье программа Speccy является творением британской IT-компании Piriform, создавшей популярную утилиту для очисти компьютера от мусора CCleaner. Спекки поможет провести диагностику железа компьютера, отображая основную информацию о каждом установленном устройстве на борту: процессоре, видеокарте, материнской плате, жестком диске и остальных комплектующих. ПО распространяется компанией бесплатно для частного использования, и может запускаться на устаревших и новых операционных системах Windows, включая XP.
Первая на обзоре в данной статье программа Speccy является творением британской IT-компании Piriform, создавшей популярную утилиту для очисти компьютера от мусора CCleaner. Спекки поможет провести диагностику железа компьютера, отображая основную информацию о каждом установленном устройстве на борту: процессоре, видеокарте, материнской плате, жестком диске и остальных комплектующих. ПО распространяется компанией бесплатно для частного использования, и может запускаться на устаревших и новых операционных системах Windows, включая XP.
После установки и первого запуска Speccy без дополнительных приветствий сразу переходит к делу – анализу установленного оборудования. Основные показатели моментально выводятся на экран во вкладке «Общая информация». В левой панели вкладок пользователь выбирает интересующее устройство. Кроме заложенных в прошивке комплектующих данных Speccy отображает текущую температуру устройства, и может предупредить владельца о критически высоких значениях. Для удобства обмена диагностическими данными в программе реализована функция снапшота данных в виде изображения или их сохранения в формате XML и TXT.
Преимущества:
- выводит информацию о типе, производителе, номере партии, годе изготовлении, версии прошивки и т.д.;
- снимает показания с датчиков температур;
- отображает номинальные и текущие частотные показатели;
- сохраняет полученную информацию в виде документа или изображения;
- имеет простой интерфейс без излишеств;
- полноценное бесплатное программное обеспечение на русском языке.
Недостатки:
- нет диагностических инструментов (тестов) для проверки стабильности системы;
- отображает неполный список параметров комплектующих.
EDR
Постепенно ряд производителей включает решения данного класса в состав уже существующих агентов – антивирусной защиты, систем защиты от утечек данных и т.д. Но оно несёт принципиально другой функционал – это дополнительная телеметрия (Detection в Endpoint Detection and Response) и возможности по реагированию (Response).
Телеметрия расширяет и унифицирует функции штатных журналов операционных систем. То, что раньше выявлялось SIEM на основе нескольких событий или не выявлялось вовсе, теперь фиксируется как единая запись агента EDR, обогащённая различными метаданными. И, насколько это возможно, не зависит от семейства и версии операционной системы, на которую установлен агент.
Реагирование средствами EDR делает процесс локальным и увеличивает его стабильность.
Так как к этому этапу у вас уже выстроены процессы обнаружения и реагирования, при оценке эффективности от внедрения EDR можно приложить решение к каждому из них и понять, какой плюс будет в конкретном случае и суммарно.
Результат использования EDR – расширенная телеметрия и локальное автоматизированное реагирование.
Датчики
ДПЛС
- С2000-ВТ — комбинированный датчик температуры и влажности для использования внутри помещений (IP41). Имеет сертификат средства измерения, погрешность всего 0,5°С и рекомендованную розничную цену всего 1200 руб.!
- С2000-СМК (и его вариации) — датчик «открытия двери» (магнито-контактный извещатель, геркон). Рекомендованная розничная цена — 300 руб.;
- С2000-ДЗ — точечный датчик затопления (делается совместно с Риэлта, поэтому корпус «неформат»). Рекомендованная розничная цена — 800 руб.;
- С2000-АР1, С2000-АР2, С2000-АР8 — адресные расширители на 1, 2 и 8 подключений, могут использоваться как «приемники» сигналов типа «сухой контакт» (вкл./откл.) с другого оборудования (например, с прибора пожаротушения или помпы кондиционера);
- С2000-СП2 — релейный блок (на 2 выхода), с помощью которого можно управлять устройствами (например, лампой сигнализации — световым индикатором). Рекомендованная розничная цена — 1200 руб.
официальном сайте производителя
FurMark
 Утилита FurMark является негласным «эталоном» для тестирования высокопроизводительных видеокарт и встроенных видеосистем компьютера на протяжении многих лет. Она представляет собой набор стресс-тестов для испытания графической подсистемы на стабильность работы и максимальную производительность в 3D с поддержкой API OpenGL. FurMark получает регулярные обновления и распространяется бесплатно.
Утилита FurMark является негласным «эталоном» для тестирования высокопроизводительных видеокарт и встроенных видеосистем компьютера на протяжении многих лет. Она представляет собой набор стресс-тестов для испытания графической подсистемы на стабильность работы и максимальную производительность в 3D с поддержкой API OpenGL. FurMark получает регулярные обновления и распространяется бесплатно.
Фур Марк состоит из диалогового окна настроек и окна теста, в котором вращается сложный рендер объекта тороидальной формы (или по-народному — «волосатый бублик»). Перед запуском тестирования необходимо выбрать уровень графики и режим работы. Кроме разрешения и сглаживания пользователь может включить полноэкранный вместо оконного режима. Важным моментом стоит указание времени проведения теста, так как длительное нахождение видеоускорителя под стопроцентной нагрузкой может вывести устройство из строя.
После нажатия кнопки GPU stress test на экране появляется вращающийся объект, для прорисовки которого потребляется весь ресурс видеокарты. В верхней части показан график изменения температуры видеоядра. В зависимости от заданных параметров тест прекращается автоматически через определенное время или в ручном режиме пользователем.
Преимущества:
- проверка видеокарты под максимально допустимой нагрузкой на стабильность, производительность, энергопотребление;
- несколько режимов «прогона» теста;
- простой интерфейс без лишних элементов;
- в составе есть утилиты GPU-Z и GPU Shark;
- бесплатное ПО.
Недостатки:
- FurMark дает предельную нагрузку на видеоадаптер, что может привести к отвалу графического чипа, чипов памяти и другим «малоприятным» последствиям;
- интерфейс не русифицирован в официальной версии.
О мониторинге в контексте метрик
Если спросить среднестатистического технаря-инженера, с чем у него ассоциируется мониторинг, то скорее всего вам ответят – «метрики приложения», и подразумеваться будет их сбор и некоторая визуализация. Причем, о изнанке этого процесса, как показал мой опыт, многие даже не задумываются – в понимании большинства «оно просто показывается в Grafana/Kibana/Zabbix/подставьте нужное».
Ответ этот, замечу, всё же не полный, поскольку одними лишь метриками всё не ограничивается. Точнее даже так: мониторинг — это не только о том, чтобы метрики собрать и вывести на дашборд. И вот с этого момента давайте поподробнее.
Из чего же сделан мониторинг?
Со временем, я для себя вывел следующие аспекты:
-
Сбор метрик из различных источников – приложения, показатели хоста, «железной» части площадки; различия в pull и push моделях пока не затрагиваем, об этом чуть позже
-
Запись и дальнейшее их (метрик) хранение в базе данных с учетом особенностей самой БД и использования собранных данных
-
Визуализация метрик, которая должна балансировать между возможностями выбранного технологического стека, удобством использования дашборд и «хотелками» тех, кому с этим всем предстоит работать
-
Отслеживание показаний метрик по заданным правилам и отправка алертов
-
В случае продвинутого мониторинга сюда можно добавить еще один пункт — выявление аномалий и проактивное информирование о деградации наблюдаемой системы на основе ML.
Dxtory
В интернете имеется не так много подходящих утилит, которые могут отображать нужную информацию. Рассмотренные уже программы самые лучшие для проведения мониторинга. Немного ниже по полярности стоит Dxtory.
В основном она занимается захватом скриншотов и записью того, что происходит на экране. Здесь присутствуют все нужные опции для создания предварительной конфигурации и настройки конкретного захвата.
В качестве дополнения выступает панель оверлея с основными данными, а именно:
• наличие счетчика кадров;
• нагрузка на видеокарту.
Если вас устраивает минимальный набор пунктов в процессе мониторинга, то можно воспользоваться данной программой.Софт имеется в свободном доступе, но имеется и платный вариант.
В нем вы не найдете каких- либо особенностей, так как программа работает в основном для поддержки ПО. Русского языка нет, но разобраться в устройстве программы вполне возможно.
Worker
Система Worker позволяет повысить производительность предприятия и значительно сэкономить средства, благодаря умному мониторингу работы персонала. Продукт состоит из трех частей: Директор (устанавливается на ПК руководителя), Агент (устанавливается на компьютерах сотрудников для сбора информации) и Сервер (здесь хранится база программы и вся сохраненная информация).
К возможностям программы относятся:
- контроль соблюдения графика работы;
- статистика использования программ и сайтов;
- хронометраж рабочего дня;
- шифрование данных индивидуальным ключом (вся собранная информация шифруется и хранится на облачном сервере в зашифрованном виде);
- график нагрузки сотрудников;
- блокировка и управление списком сайтов и программ;
- скриншоты рабочего стола компьютера и веб-камеры.
Сервис предлагает возможность пробного бесплатного использования полнофункциональной демо-версии.

Screenshot monitor
О программе Screenshot monitor
Основное предназначение программы Screenshot Monitor, как видно даже из названия, это периодические снимки мониторов сотрудников, которые отправляются руководителю. Количество скриншотов, производимых программой за час, зависит от выбранного тарифа. В бесплатной версии программы доступны 3 скриншота в час. Помимо скриншотов, в бесплатной версии программы есть функция учета рабочего времени. Программа весьма демократична по сравнению с вышеперечисленными продуктами, к примеру, у сотрудника есть возможность удалять скриншоты, на которые попала личная информация.
Количество подконтрольных компьютеров:
В бесплатной версии программы доступен мониторинг до 3 компьютеров сотрудников.
- Отчеты по рабочему времени.
- Скриншоты экранов компьютеров сотрудников (3 скриншота в час).
- Время хранения скриншотов – 2 недели.
Какие функции доступны только в платной версии:
Платная версия программы позволяет анализировать уровни активности пользователей, приложения и используемые url. Pro-версия программы делает до 30 скриншотов в час и хранит их в течение года.
Что нам стоит SOC построить
Чем выше бюджет проекта, чем больше проект политизирован, тем сложнее изменить его вводные. Но для решения вопросов безопасности тоже действует принцип Парето. Добивать самые трудоёмкие 1-5-10% договора, которые не будут заметны в общем результате, не выгодно ни одной из его сторон. Проект лучше разбивать на этапы, а не гнаться за постройкой условного SOC с нуля. Это позволит учесть опыт предыдущих стадий и минимизировать риски по реализации нереализуемого, а часто и не нужного.
Итоговые цели нужно как ставить, так и пересматривать. А когда они зафиксированы в договоре, это практически невозможно. Например, база данных, с которой по грандиозному плану будут собираться события аудита, упадёт под дополнительной нагрузкой, вызванной этим самым аудитом. Но в техническое задание уже заложено требование по написанию ранбука на основе данных источника и реализации его в IRP. Переходим к правкам по ходу пьесы?
Декомпозицию на этапы можно производить вплоть до подключения «вот этих 5 видов источников» или создания «вот этих 10 сценариев и ранбуков к ним». Главное – это не полнота внедрения, а полнота использования того, что внедрено. Обосновать модернизацию эффективного решения проще, чем того, которое всплывает два раза в год в негативном контексте и стоит в десять раз дороже.
Если не знаете, что точно хотите и можете получить от автоматизации – просите пилотный проект. Но если не понимаете, что вам надо «без автоматизации» – от кого будете защищаться, куда и как ему было бы интересно проникнуть, что вам с этим делать – преимуществ от пилота будет мало. В технической части вы, вероятно, совершите скачок. Но подходит ли вам конкретный продукт – сказать будет сложно. Тут нужен консалтинг, а не внедрение технических решений. Пока вы не определитесь, что хотите автоматизировать, выбор конкретной системы не будет обоснованным. То, что показалось достаточным в ходе сегодняшнего пилота, завтра придётся подпирать костылями.
Пилот должен проводиться в рамках разумного. Я знаю организацию, которая столкнулась с невозможностью масштабирования после закупки. Не первый раз просят пилот, в котором у SIEM 30 графических панелей, 40 видов источников, 50 правил корреляции и 60 отчётов. Сделайте, а мы подумаем, покупать или обойдёмся. Интересы сторон должны сходиться. В той же части масштабирования можно согласовать решение с производителем и, например, заручиться от него гарантийным письмом.
ПРИНЦИП РАБОТЫ РАСПРЕДЕЛЕННОГО МОНИТОРИНГА СЕТИ
Работа программы основывается на периодическом опросе хостов, находящихся в базе данных, путем последовательного выполнения заданных для каждого из них проверок. В зависимости от результата выполнения этой процедуры, проверки получают статус (пройдена, не пройдена), результаты записывается в базу данных.
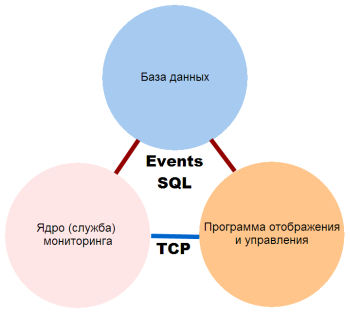
- С помощью графической консоли или web-интерфейса создаётся база данных хостов и проверок.
- Служба мониторинга принимает введённые данные и начинает циклическое выполнение проверок, обновление их статуса в БД, формирование базы статистики времени выполнения проверок и значений параметров (напряжение, память, загрузка процессора и так далее).
- Графическая консоль получает статус выполненных проверок и отображает его в виде цветовой раскраски списка, строит графики, формирует отчёты на основе накопленной статистики.
- В случае сбоя служба инициирует выполнение действий: запись в журнал (в базе данных и дублирование в файловый, локальный), SMS, E-mail, перезапуск / останов служб и компьютера, выдача сообщения на экран, проигрывание звукового файла, запуск внешних программ и команд с параметрами. Выполнение последних трёх действий служба делегирует графической консоли, поэтому она должна быть запущена в это время.
- Система при проверке хостов сети использует множество стандартных протоколов: SNMP, TCP, ICMP, ARP, HTTP, FTP, WMI, NetBIOS. В случае, если данные от хоста служба не может получить удалённо (к примеру, температуру процессора или параметры S.M.A.R.T. жёстких дисков и SSD NVMe), то на помощь приходит удалённый агент. Будучи запущенным в виде службы на удалённом хосте, он локально получает всю необходимую информацию и отдаёт её службе по запросу.
- Web-интерфейс практически дублирует функции графической консоли в браузере. Можно подключиться к web-серверу программы с любого мобильного устройства, ноутбука или компьютера, посмотреть статус проверок, журналы, построить графики, изменить параметры.
Все настройки и результаты проверок хранятся в единой SQL базе данных. Центры (сервера) мониторинга в удалённых сетях взаимодействуют с базой данных самостоятельно из разных подсетей. При этом вся система может быть развернута внутри частной сети предприятия по схеме «Private Cloud», обеспечивая все удобства облачной системы мониторинга и не нарушая безопасность сети.
Кроме повышения надёжности, распределённая схема контроля позволяет выполнять централизованную проверку нескольких удалённых сетей, со сбором статистики в одной базе данных. Необходимо лишь установить на сервере каждой удалённой сети службу мониторинга и настроить на нём связь с базой данных (два TCP-порта — 3050 и 3051).
Нормальная температура комплектующих
В каких же пределах должна держаться температура для различных комплектующих.
Процессора
- До 42 oC. Процессор в режиме простоя.
- До 65 — 70 oC (в зависимости от модели). При нагрузке.
- До 61 — 72 oC (в зависимости от модели). Максимально рекомендуемая.
А также:
- 94 — 105 oC. Включение троттлинга — снижения производительности.
- Более 105 oC. Выключение компьютера с целью предотвращения сгорания.
Обратите внимание, что данные показатели могут постоянно меняться, так как меняются технологии. Если необходимо узнать точную информацию по конкретному процессору, можно воспользоваться подсказками в различных программах, например, в представленной выше Core Temp:

Таким образом, данные цифры условны — норма зависит от производителя (Intel, AMD …) и конкретной модели. Также, норма для процессоров большинства ноутбука ниже. Правильнее всего зайти на страничку конкретного процессора и посмотреть его норму по температуре.
Видеокарты
В большей степени, рабочая температура видеокарты зависит от ее класса — для точного определения стоит изучить документацию. Средние показатели, примерно, следующие:
- До 45 oC. В режиме простоя.
- До 85 oC. При нагрузке.
- До 100 oC. Максимально рекомендуемая.
Свыше 100 oC видеокарта запускает процесс троттлинга и, если он не помогает — выключает компьютер.
Диска
- До 45 oC. В режиме простоя.
- До 53 oC. Максимально рекомендуемая.
При температуре выше 53 градусов значительно увеличивается амортизация диска, что приводит к ускорению его выхода из строя. Максимально допустимый порог SSD дисков чуть выше и может доходить до 70 градусов.
Минимальная рабочая температура диска должна быть в пределах 24-26 градусов. При более низких показателях возможны повреждения. Поэтому, если мы принесли с улицы холодный носитель, не стоит его сразу использовать в работе. Таким образом, комфортная температура для диска — от 25 до 45 градусов по Цельсию.
Данные цифры справедливы как для внутренних дисков, так и внешних, так как, по сути, последние — это те же самые диски, помещенные в отдельные боксы.
UBA или UEBA
Некоторые решения данного класса являются самостоятельными продуктами. Но многие вендоры SIEM предоставляют его в виде модуля. Кто-то говорит, что он заменяется набором правил (а кто-то даже заменяет). Какие возможности даёт это техническое средство?
Если в двух словах – это антифрод, только более универсальный. Идеи в основе схожи. Если подробнее – каждое подозрительное действие, совершенное пользователем (User в User Behavior Analysis) или и пользователем, и сущностью (Entity в UEBA; чаще всего это хост), приводит к добавлению баллов. После достижения определённой суммы создаётся подозрение на инцидент или аналитик сам следит за ТОП10-20-50 подозрительных пользователей. «Репутация» обеляется со временем. Например, сумма баллов уменьшается на фиксированную величину или процент каждый час. Работа с такими данными не отличается от стандартных подозрений на инциденты.
Такой подход полезен в двух случаях:
Индикаторы, считающиеся подозрительными, не могут в одиночку свидетельствовать о возникновении инцидента.
Использование статистики или машинного обучения (такими границами производители обозначают алгоритмы в составе решений) над вашими данными выдвигает и проверяет гипотезы, которые сложно тестировать вручную или с помощью корреляции. Например, сравнение сущности с остальными представителями ее группы. Почему сотрудник маркетинга ходит на какой-то ресурс, если его коллеги этого не делают? Ему нужны такие полномочия? На AD DC в 2 раза больше попыток аутентификации, чем на других
Это ИТ или ИБ проблема? Важно сформировать вводные для алгоритмов – от пороговых значений, до групп сущностей.
Результат использования U(E)BA – выявление угроз методами с высоким ЛПС или методами, для которых невозможно создать и поддерживать простой алгоритм без ущерба для качества обнаружения инцидентов.